

测试硬件和配置
对于游戏玩家来说,选择AMD显卡往往会更有性价比,那么随着目前AI渗透式爆发增长,AMD显卡在这方面表现到底又如何呢?是不是也具备性价比?我们今天就来探讨一下,值得一提的是,本篇内容会分为AIGC(AI生成内容)和LLM(大语言模型)这两个最备受关注的AI领域进行测试。

压制锐龙7 7700X的CPU散热器是微星MEG CORELIQUID S360战神,定位旗舰360水冷,整体由采用纯黑性能风扇+2.4英寸IPS显示屏组成,水泵方案来自老伙计Asetek七代,冷头上还内置了一个60mm风扇,可以为主板周边散热。

为了驱动锐龙7 7700X和RX 7900 XT的高端组合,配备了来自微星的MPG A1000G PCIE5电源,它最大的亮点就是兼容PCIe 5.0和ATX 3.0标准,拥有原生12VHPWR 16pin供电接口,最高可输出600W,加上本身拥有10年质保售后,可很好适配现今及未来的旗舰显卡。

其他硬件和配置方面,锐龙7 7700X直接开启PBO技术,使用EXPO超频达成DDR5 6000C34 16G*4,总计64GB内存容量,本次测试安装的是AMD Adrenalin 24.3.1最新版本显卡驱动(中间有加入去年23.11.1版本的简单测试环节),操作系统是Windows 11 23H2版本,最后在BIOS中开启Resizable BAR技术提升一些显卡性能。
Stable Diffusion不同分辨率出图性能

首先来测试一下目前最为火热的AIGC应用——Stable Diffusion AI绘画,目前对于AMD显卡来说有好几种部署形式,简单来分析一下吧。
第一种是DirectML SDK,插件支持不错,效率是最低的,有整合包。
第二种是通过Microsoft Olive转换成ONNX,效率挺高的,但插件支持不完善,部署起来繁琐。
第三种是Ubuntu系统+AMD ROCm,效率和兼容是最好的,不过部署同样繁琐,也不是大部分普通用户熟悉的Windows系统。
第四种就是最近比较流行的ZLUDA插件,效率仅次于第三种,也有整合包更适合大部分普通用户,本文就以这种形式进行测试的。

ZLUDA插件部署很简单,只要下载最新版本的绘世整合包,安装前置的AMD HIP SDK(不需要安装专业版显卡驱动),就可以在整合包界面——生成引擎这里看到ZLUDA已经部署完毕,下面来看看Stable Diffusion AI绘画六种设置的测试结果。
AbyssOrangeMix2深渊橙模型
正向提示词:1girl,long hair,pink hair,game game cg,full body,best quality,masterpiece,realistic,8K wallpaper,beautiful and aesthetic,detailed background
反向提示词:nsfw,ugly,low quality,low res,bad bad proportions,EasyNegative,missing arms,extra legs,too many fingers,extra arms and legs,text,username
采样方法:DPM++ 2M Karras
迭代步进:20
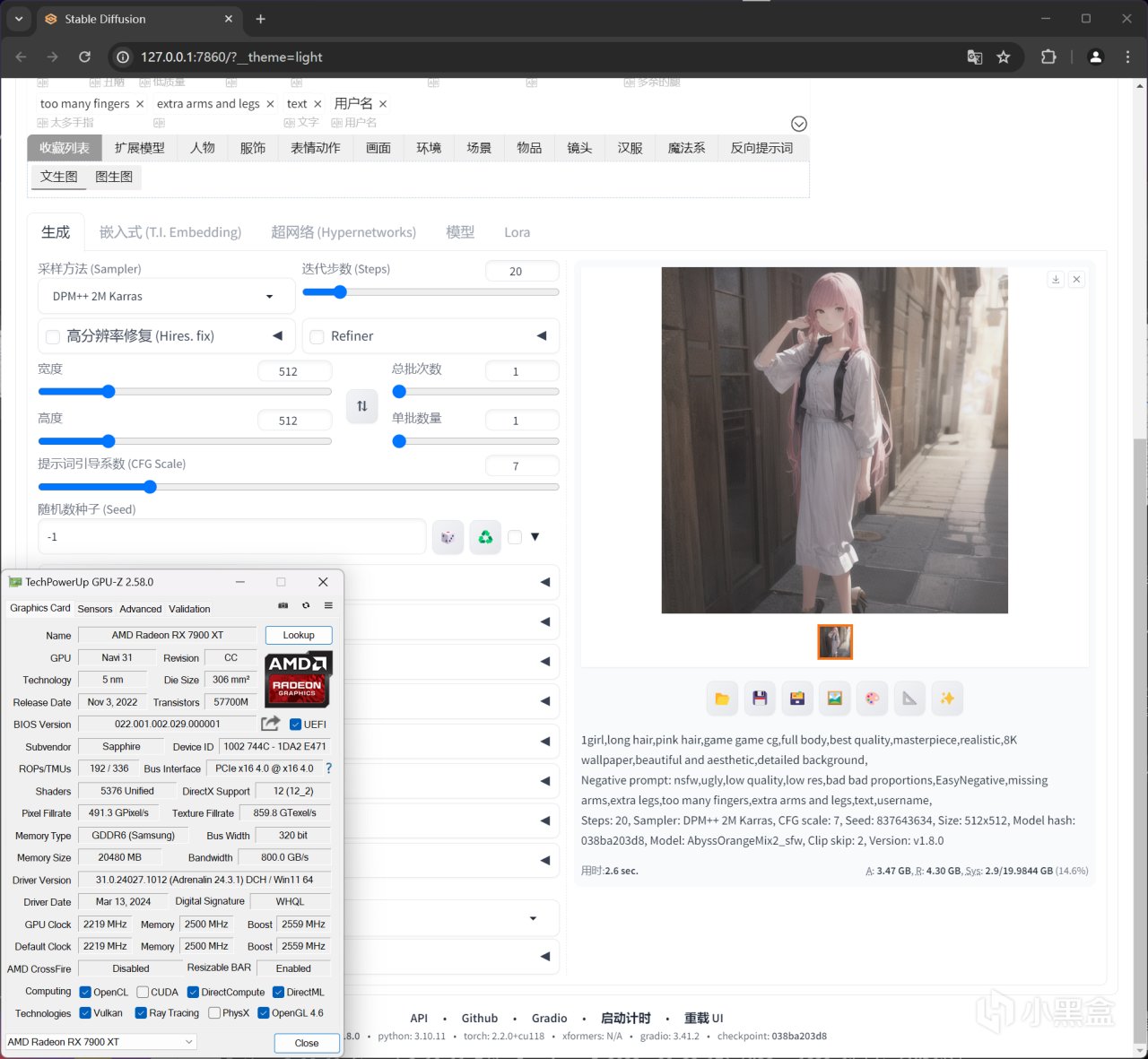
分辨率设置:512X512,总批次:1,单批数量:1,RX 7900 XT出图用时2.6秒

分辨率设置:768X768,总批次:1,单批数量:1,RX 7900 XT出图用时7.4秒
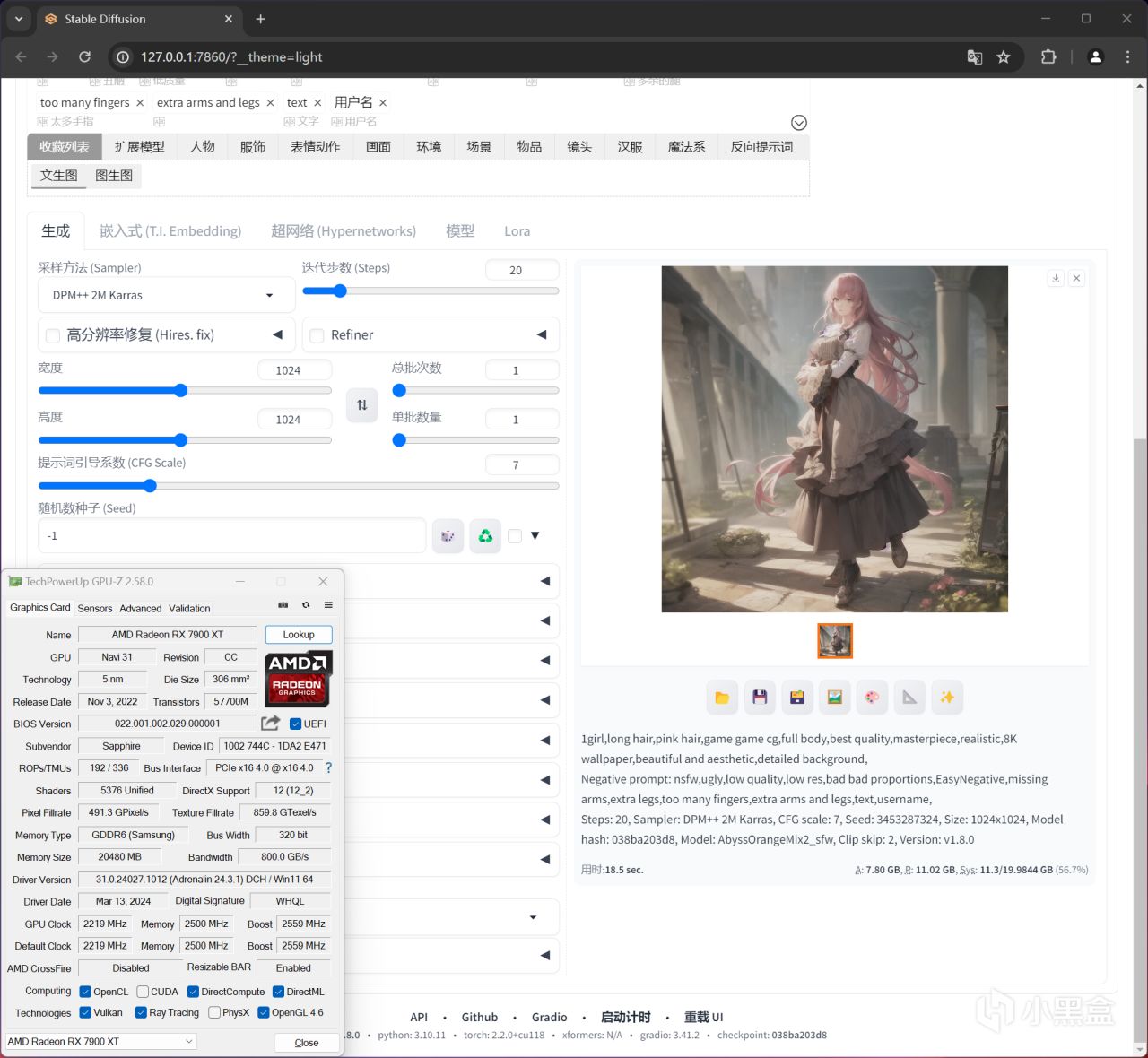
分辨率设置:1024X1024,总批次:1,单批数量:1,RX 7900 XT出图用时18.5秒

分辨率设置:1920X1080,总批次:1,单批数量:1,RX 7900 XT出图用时1分5秒

分辨率设置:1024X1024,总批次:3,单批数量:6,RX 7900 XT出图用时5分16秒
RX 7900 XT在ZLUDA加持下,各分辨率出图情况都还不错,尤其是基础的单张512X512,在体感上就是秒出,单张1024X1024设置以下能在20秒内完成,而且还可以支持到1920X1080这种分辨率。结论显而易见,ZLUDA插件是目前A卡在Windows系统下的最优解方案,它兼容性和效率都不错。

在1024X1024分辨率项目中,RX 7900 XT甚至可以实现一批次生成六张图,分成三个批次进行也没有任何问题,显存只用到17GB,20GB大显存当然是绰绰有余,可以实现多线操作,能跑起来才是王道嘛。
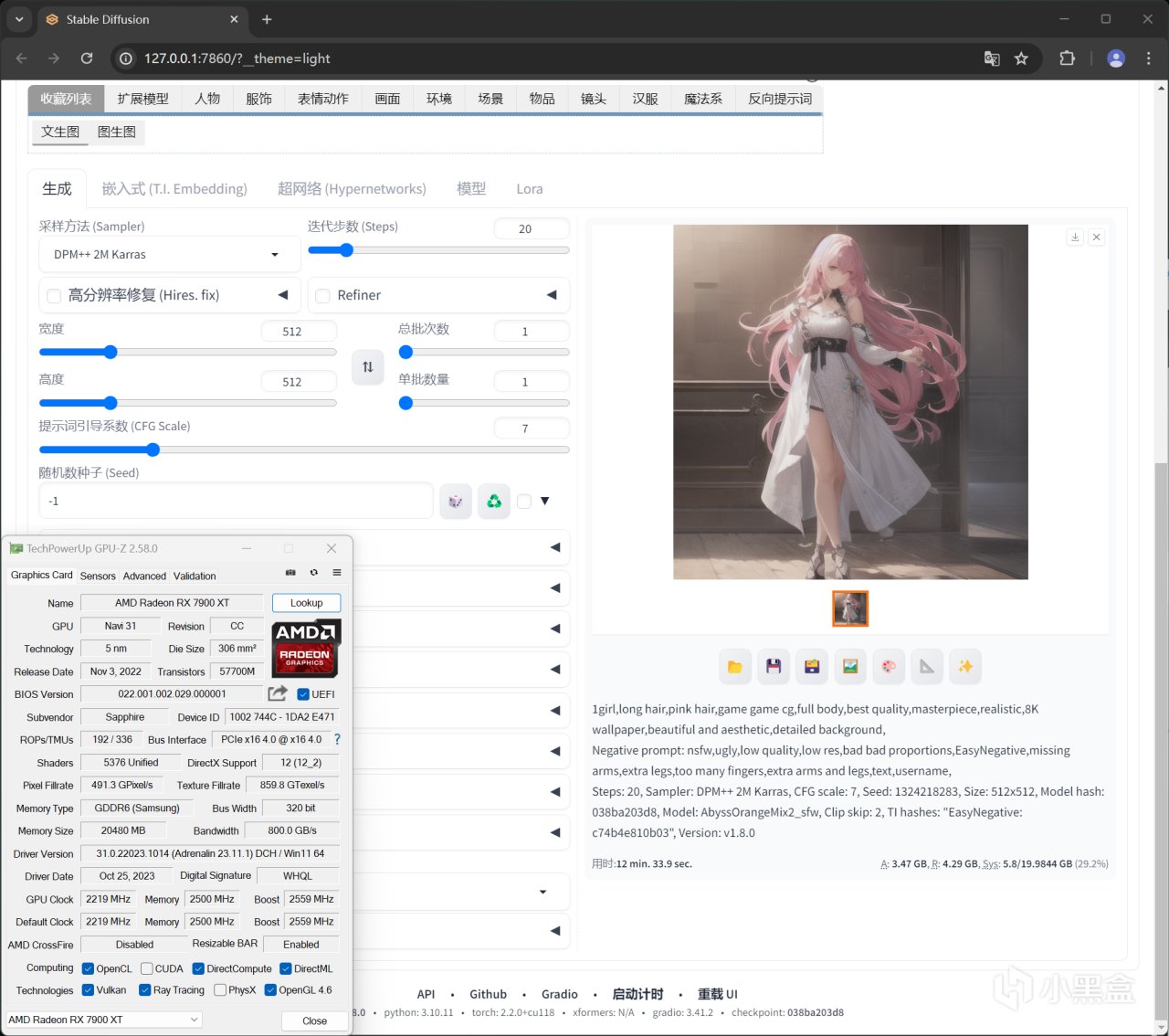
硬核还测试了去年12月份的AMD Adrenalin 23.11.1显卡驱动,结果是和目前最新版本没什么大区别,唯一就是旧驱动在首次使用ZLUDA编译会更慢一些,对于现阶段AMD显卡来说,完善Stable Diffusion的各种插件生态才是首要重心了,尤其是在Windows环境下的AMD ROCm支持。
Topaz Video AI基准测试

第二个AIGC应用则是Topaz Video AI,硬核经常用它来修复一些低分辨率的“粤语残片”,下面来简单看看RX 7900 XT在输入1080P分辨率的基准跑分。

RX 7900 XT输入分辨率1080P,各项模型的跑分性能
在Topaz Video AI常用的四个模型——插帧方面的修复常用模型是Apollo和Chronos,而图像方面的修复常用模型是Proteus和Gaia,从测试结果来看,RX 7900 XT用来修复1080P分辨率视频效率相当不错,跑起来就是入门级显卡的好几十倍了,20GB大显存海量储备足够可以喂饱。
Mistral-7B和通义千问1.5-14B/32B/72B四种大模型性能测试
第三个测试项目是LM Studio,这是一款可搜索并下载在本地运行LLM(大语言模型)的应用,并可兼容OpenAI API的接口,它省去了Python复杂的配置过程,也是免费开源的,重点它是本地部署,可以更好保护个人隐私。
LM Studio对于AMD硬件也是相当友好,现今拥有支持锐龙处理器NPU硬件加速(包含AMD OpenCL)和AMD ROCm显卡加速的两种软件版本,对于RX 6800以上的AMD显卡来说,强烈推荐后者版本,效率完全不是一个概念,下面来看看RX 7900 XT运行7B、14B、32B、72B四种不同参数量的大模型效能如何吧。
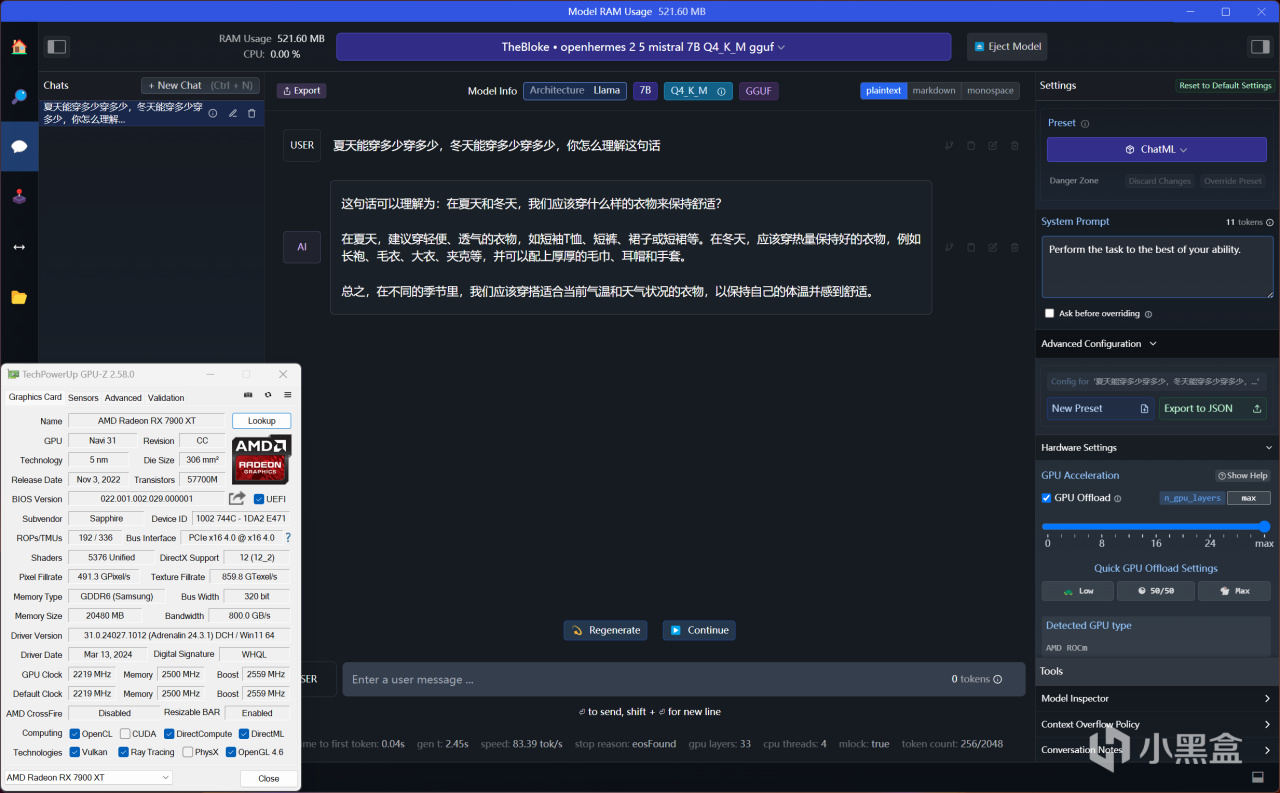
Mistral-7B,RX 7900 XT使用AMD ROCm加速,推荐GPU负载数值MAX,推理速度为83.39 tok/s
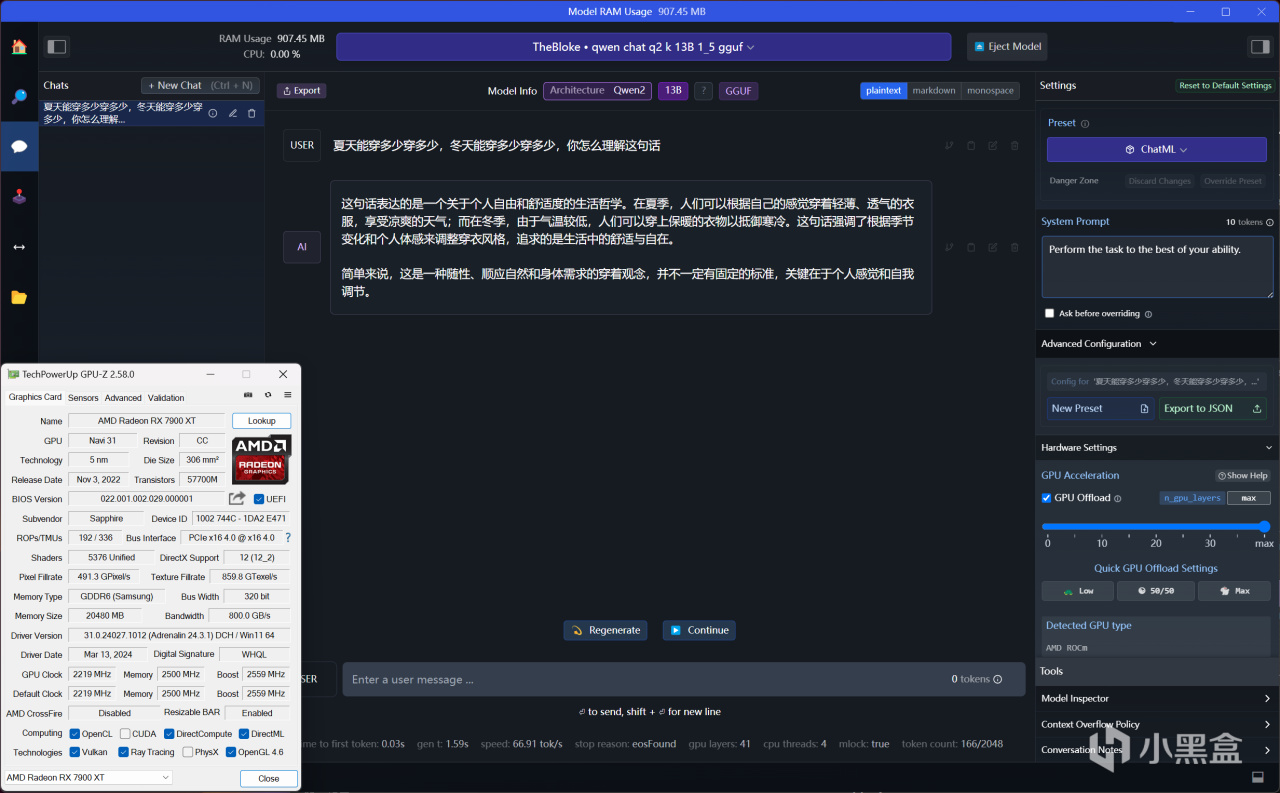
通义千问1.5-14B,RX 7900 XT使用AMD ROCm加速,推荐GPU负载数值MAX,推理速度为66.91 tok/s
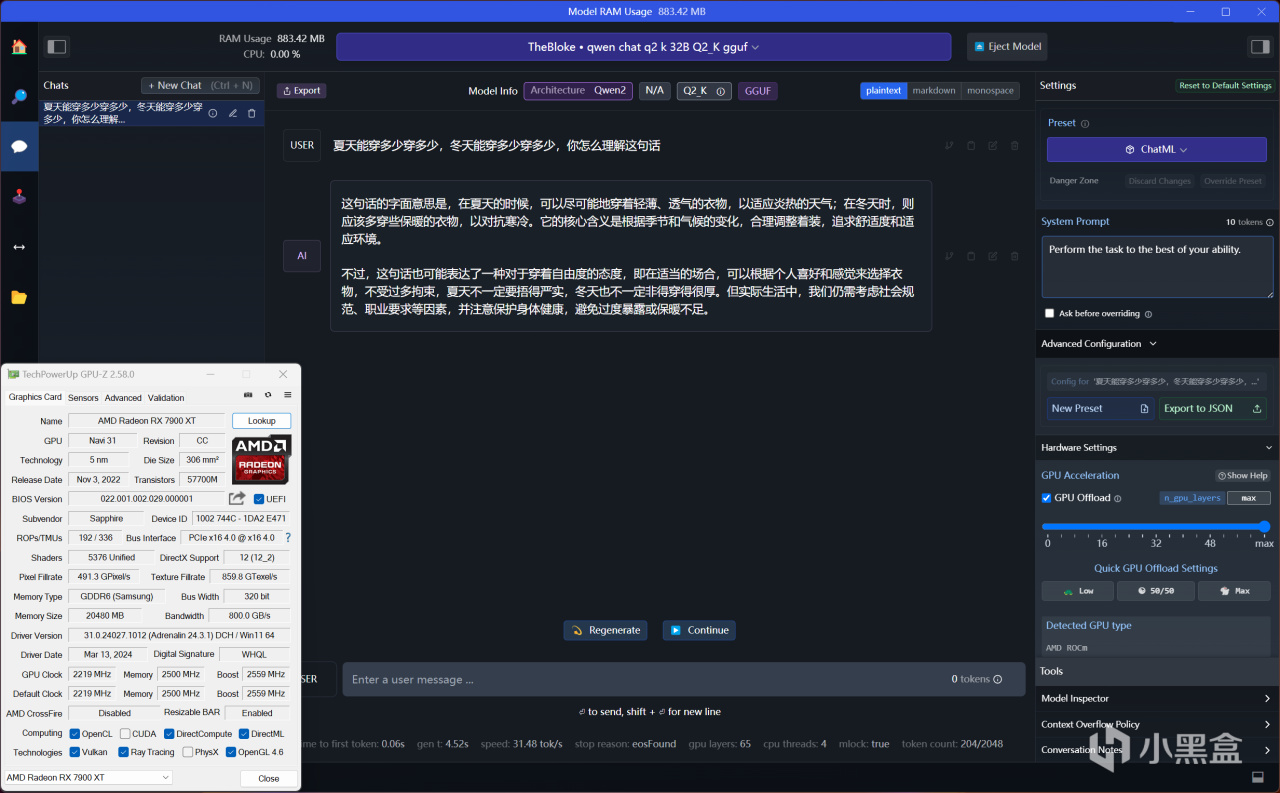
通义千问1.5-32B,RX 7900 XT使用AMD ROCm加速,推荐GPU负载数值MAX,推理速度为31.48 tok/s
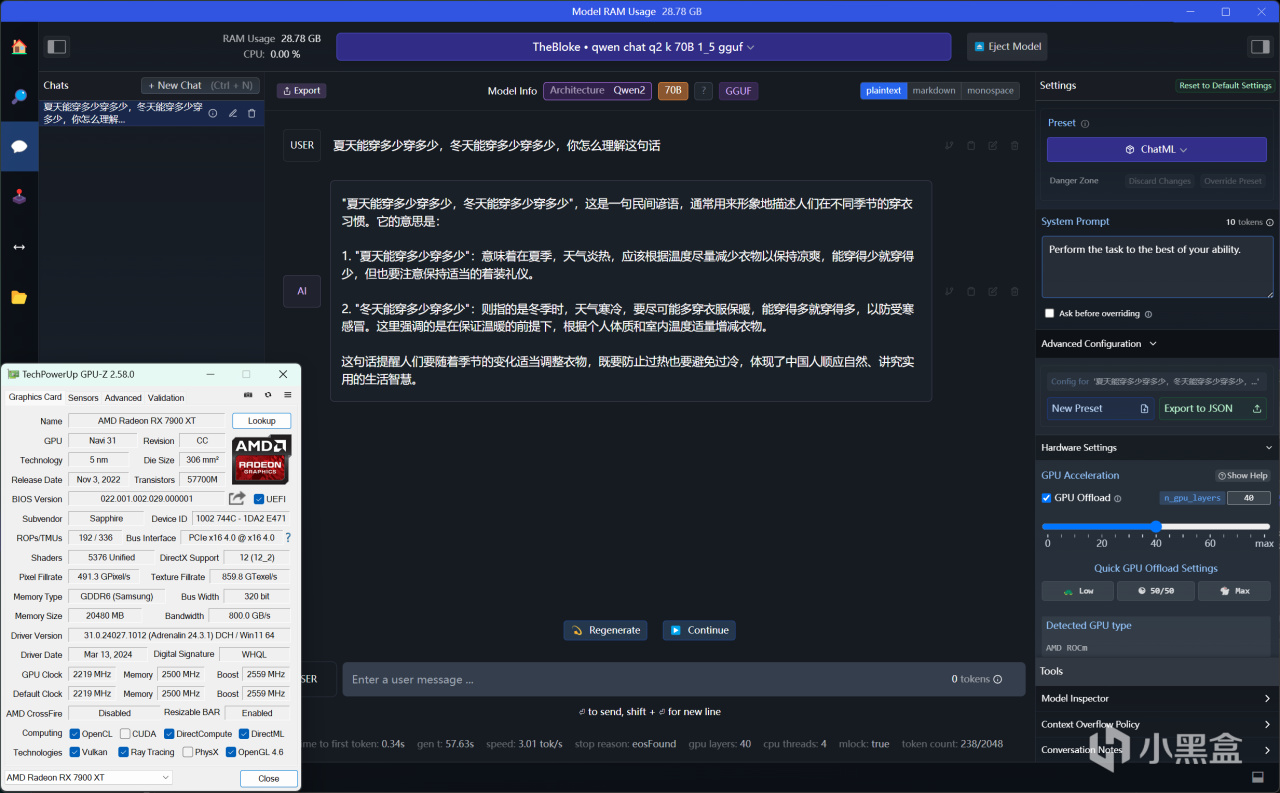
通义千问1.5-72B,RX 7900 XT使用AMD ROCm加速,推荐GPU负载数值40,推理速度为3.01 tok/s
首先,在上述答案中,可以看到模型的参数量越大,AI回答的令人满意程度就越高,而在运行72B参数量时(至少是能跑起来),由于远远超出了RX 7900 XT的负载能力,偶尔AI回答有时候会抽风,正常的时候和32B参数量用起来没什么区别。而32B参数量回答问题的体感也是秒回,AI生成文字的速度稍微比7B慢一丢丢,完全是不影响爽快体验的。
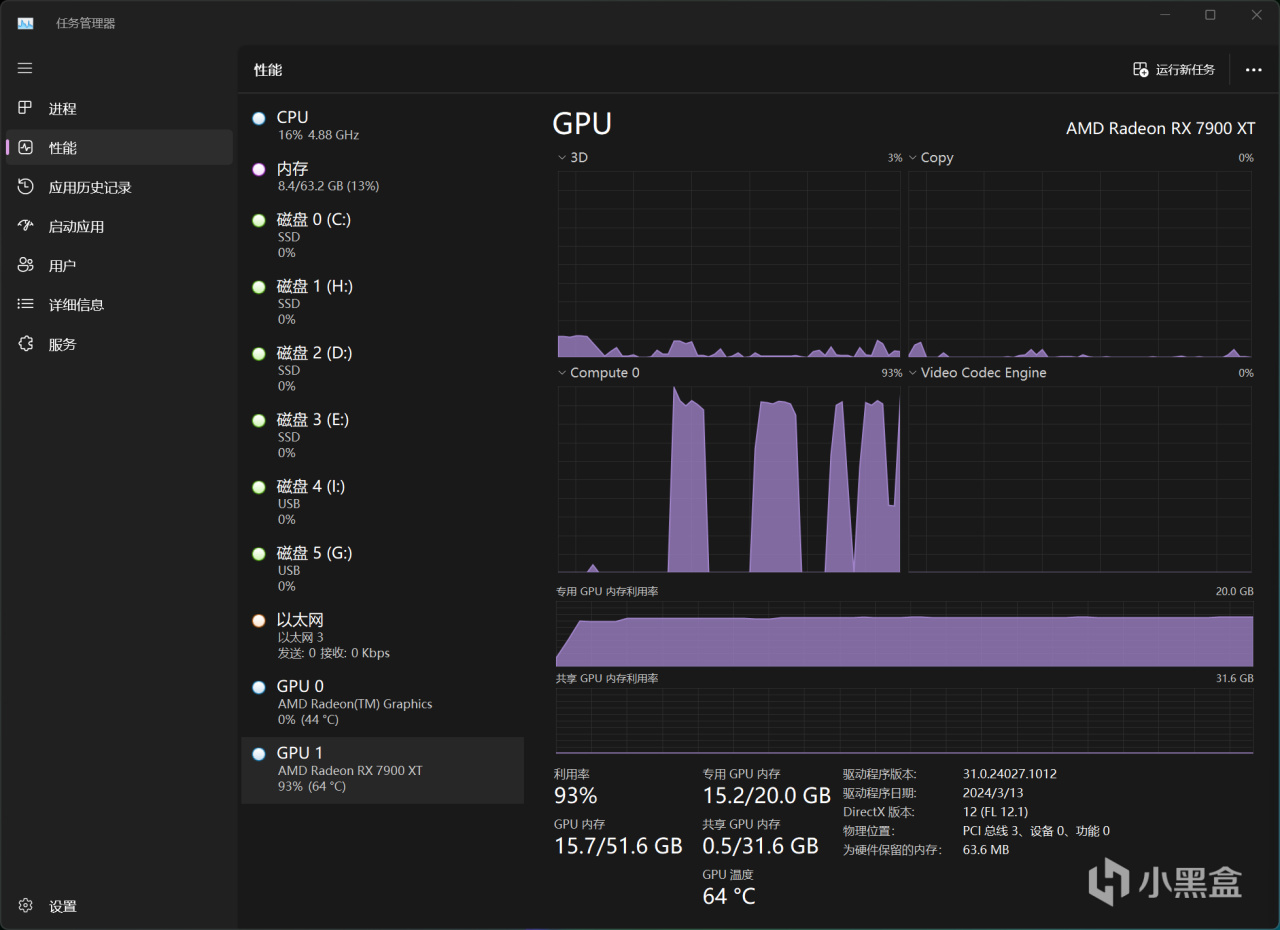
通义千问1.5-32B,RX 7900 XT使用AMD ROCm加速,GPU负载可以用到90%以上,显存则是15GB,可以充分把显卡性能榨干了,再次证明20GB大容量显存的优势之处,硬核比较好奇的是,如果是16GB显存的显卡,性能表现又会如何呢?
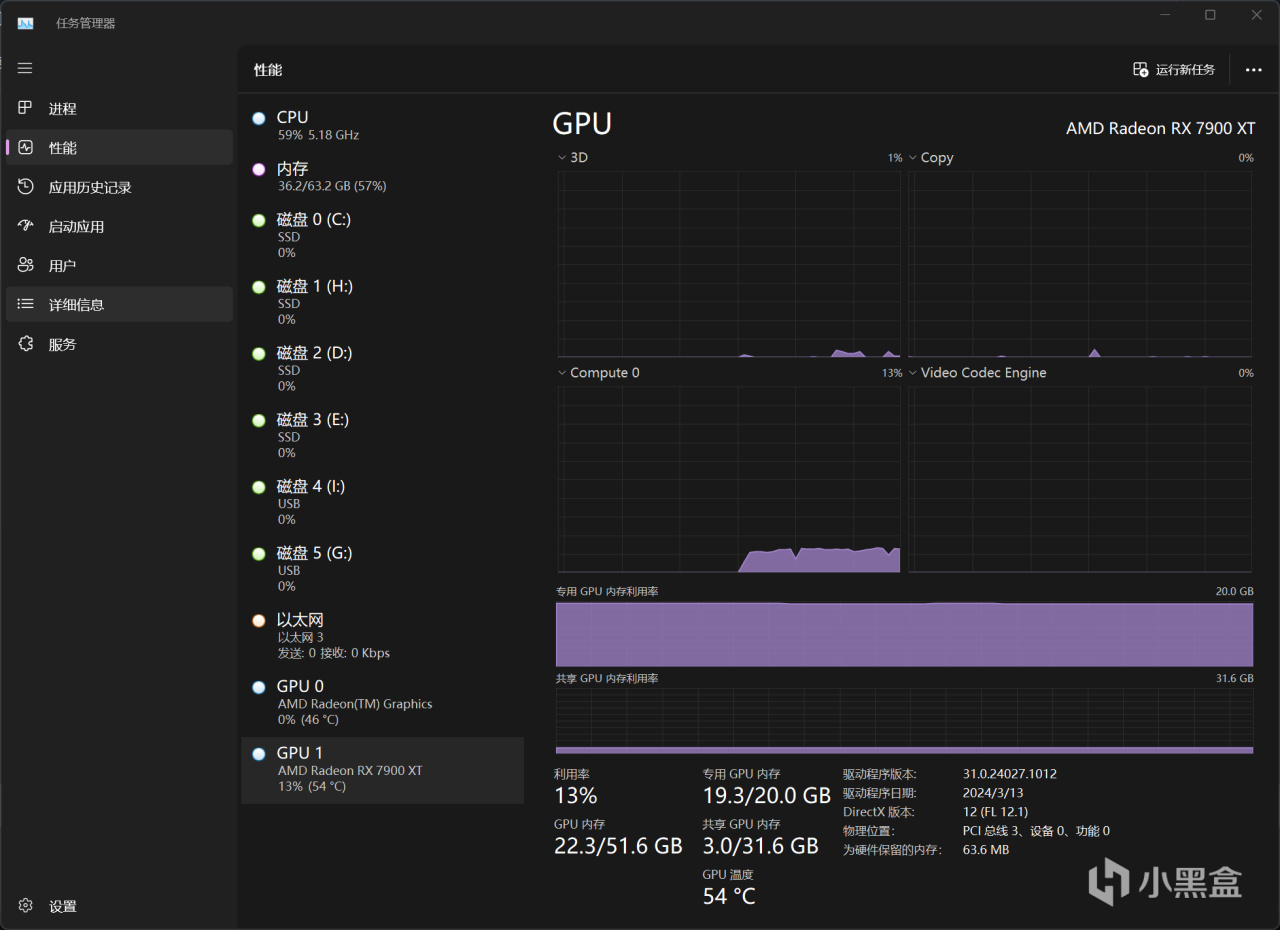
通义千问1.5-72B,对于RX 7900 XT来说,GPU负载数值是不能超过40的,否则就会出现报错警告,运行它时内存占用达到36GB,但是效率却上不去,这种恐怖如斯的参数量,一般都是多张专业卡才能跑得爽了。
结语

目前AMD RX 7900 XT这款显卡售价在5K价位,它在游戏性能方面可以比肩RTX 4080 SUPER了,性价比是相当高的,而经过本文实测,RX 7900 XT在AIGC(AI生成内容)和LLM(大语言模型)领域的性能表现,完全是对得起它的售价,它拥有20GB GDDR6X超大显存容量,可以运行一些数据量更大的项目,我们也看到了AMD ROCm在Windows系统中可以发挥强大的AI算力,期待AMD可以继续加大优化的力度吧!总得来说,RX 7900 XT是挺适合追求性价比的游戏玩家和AI专业用户。
#免责声明#
①本站部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责。
②若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
③如果本站有侵犯、不妥之处的资源,请联系我们。将会第一时间解决!
④本站部分内容均由互联网收集整理,仅供大家参考、学习,不存在任何商业目的与商业用途。
⑤本站提供的所有资源仅供参考学习使用,版权归原著所有,禁止下载本站资源参与任何商业和非法行为,请于24小时之内删除!

