

引言
截止到10月份,国内已发布的大型模型数量达到了238个,这一数字在6月份时仅为79个,这意味着在短短的4个月里,大模型的数量增长了三倍。此外,相关数据显示,截至2023年10月,在Hugging Face平台上可供下载的文本生成模型数量已经接近3万。
那么,在这么多模型中,国产模型与国外知名的模型差距又有多大呢?与ChatGPT相比,国产模型又有哪些优势呢?
AI模型的分类
在对各个模型作出比较前,我们先要了解模型的分类。
监督学习模型:这种类型的模型在训练过程中需要有标签的数据,即每个输入样本都有一个已知的正确输出。常见的监督学习模型包括线性回归、逻辑回归、支持向量机(SVM)、决策树、随机森林等。
无监督学习模型:与监督学习不同,无监督学习的训练数据没有标签,模型需要自己发现数据中的模式和结构。常见的无监督学习模型有聚类算法(如K-means)、自编码器(Autoencoder)、受限玻尔兹曼机(RBM)等。
半监督学习模型:这类模型介于监督学习和无?监督学习之间,它可以在有限的标注数据和大量的未标注数据上进行训练。代表性模型有生成对抗网络(GANs)、卷积神经网络(CNN)等。
强化学习模型:强化学习是一种通过环境反馈来学习策略的机器学习方法。在这种方法中,智能体根据其行为的结果来调整策略以最大化某种奖励信号。著名的强化学习模型包括Q-learning、Deep Q-Network (DQN) 和Proximal Policy Optimization (PPO) 等。
深度学习模型:这是近年来最热门的人工智能领域之一,利用多层神经网络处理复杂任务。常见的深度学习模型有卷积神经网络(CNN)用于图像处理,循环神经网络(RNN)和长短时记忆网络(LSTM)用于序列数据处理,以及变分自编码器(VAE)和生成对抗网络(GAN)等。
大语言模型:这是最近几年兴起的一种新型深度学习模型,它们通常基于Transformer架构,并经过大规模文本数据集的预训练。这些模型有能力理解和生成自然语言,可以用于问答、翻译、摘要等多种NLP任务。代表性的大语言模型有GPT系列(如GPT-3、GPT-4)、BERT、Turing NLG、阿里云的通义千问等。
在本篇中主要针对国内外大语言模型进行比较评测。
榜单
尽管评测榜单的权威性仍有待验证,但它为我们提供了一个评估和比较大模型性能的视角。
MMLU
在国际上,MMLU(Massive Multitask Language Understanding)是广泛使用的评测集之一。这个测试集由加州大学伯克利分校的研究人员于2020年9月发布,包含57个不同的任务,涉及初等数学、美国历史、计算机科学、法律等多个学科领域。这一基准测试旨在通过仅在zero-shot和few-shot设置中评估模型来衡量预训练期间获得的知识。这使得基准测试更具挑战性,并更类似于我们如何评估人类。
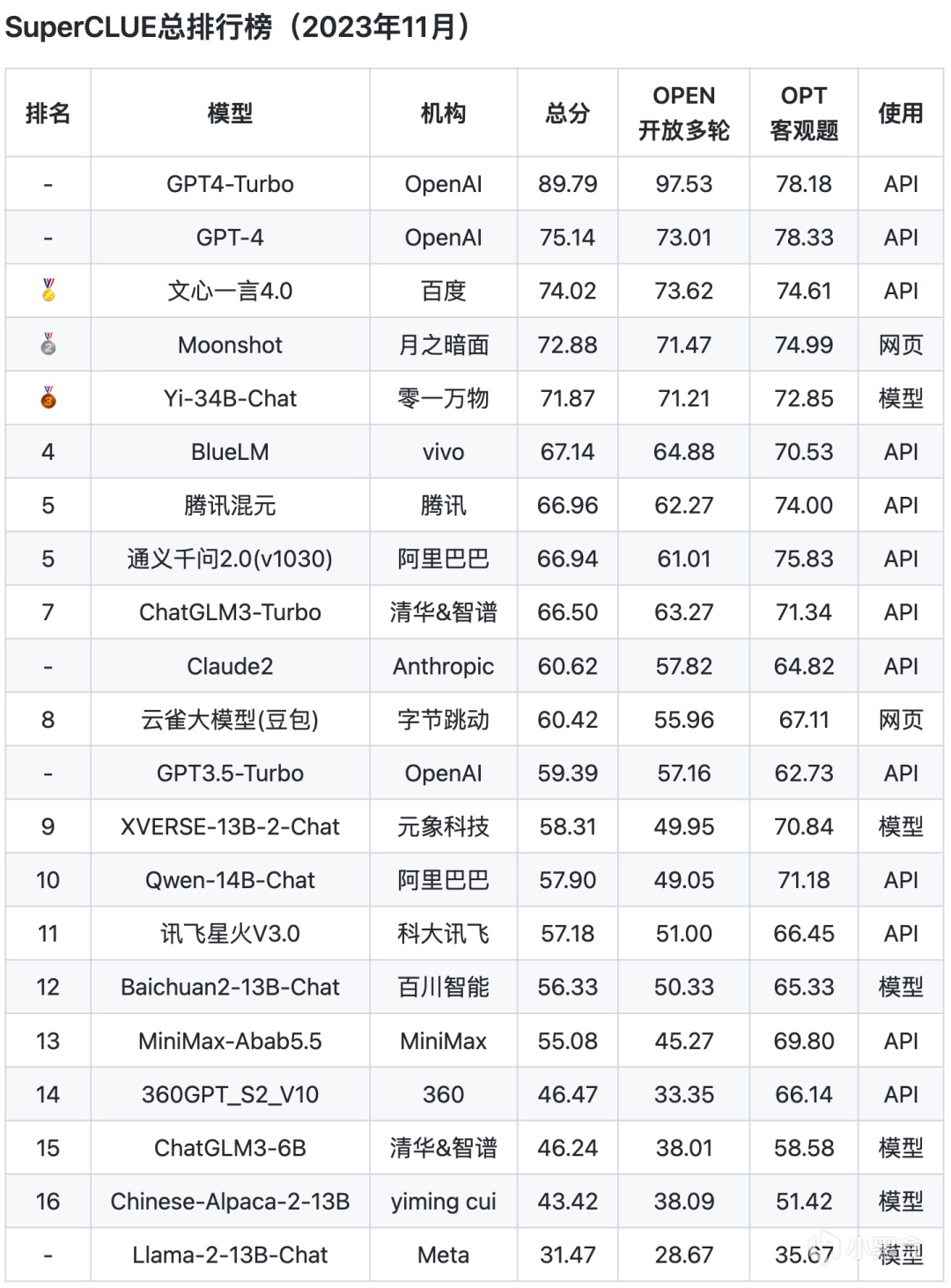
总排行榜
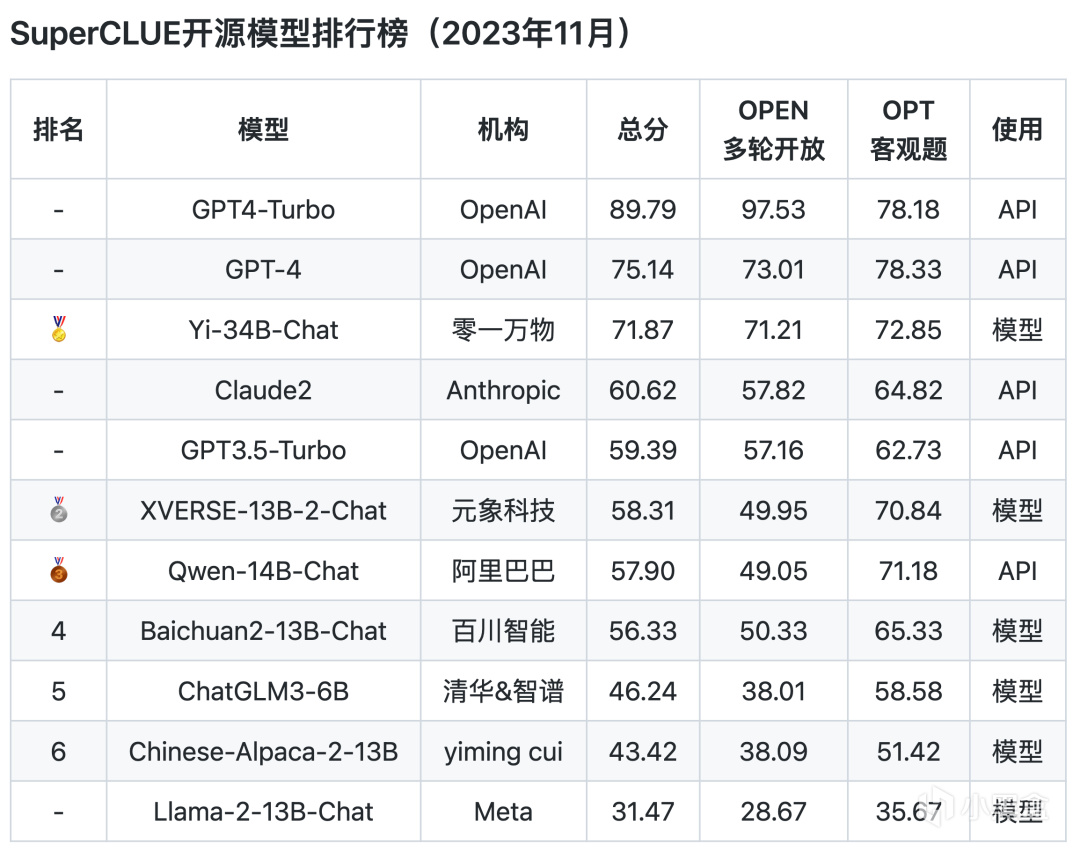
开源模型排行榜
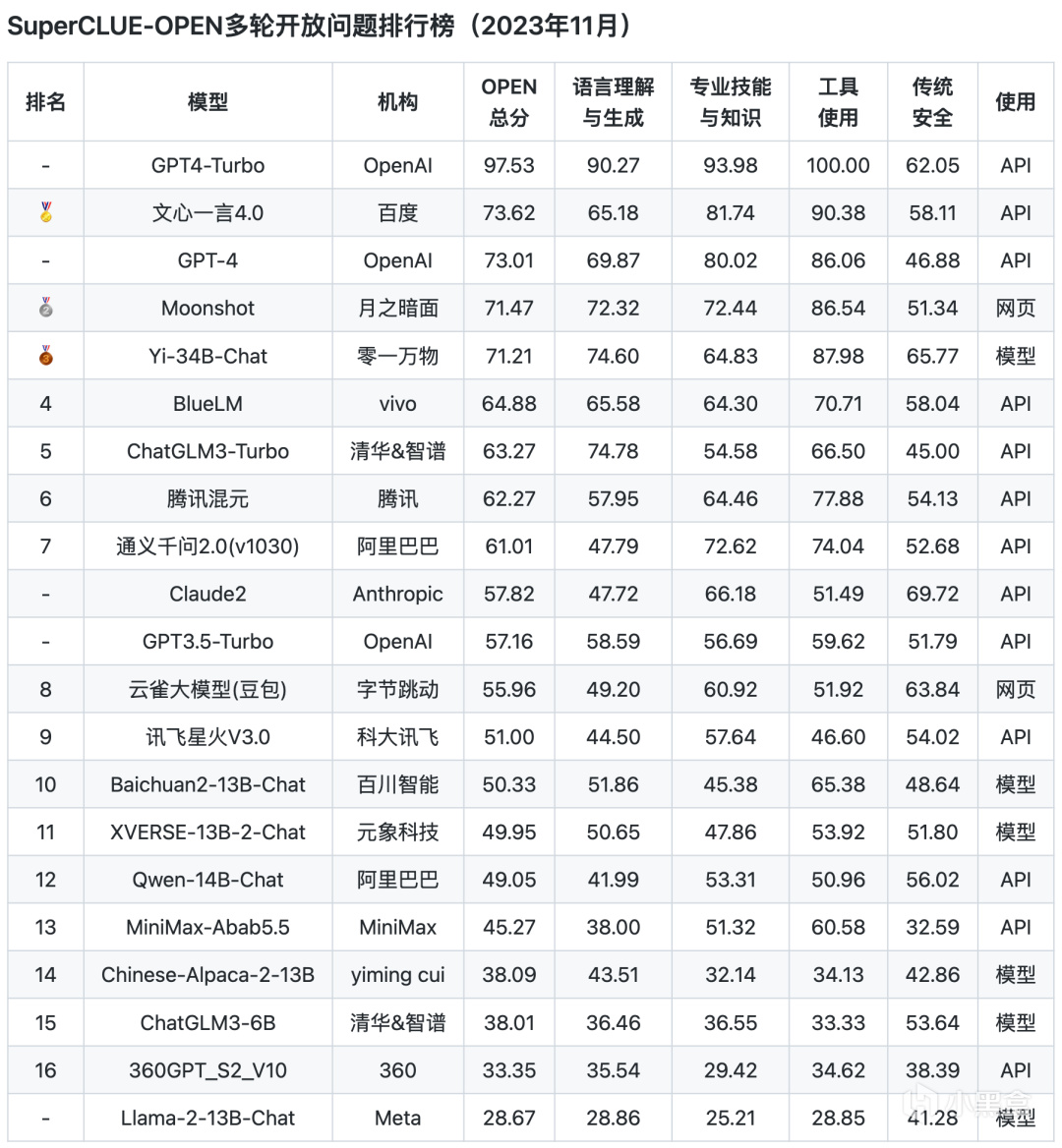
多轮开放问题排行榜
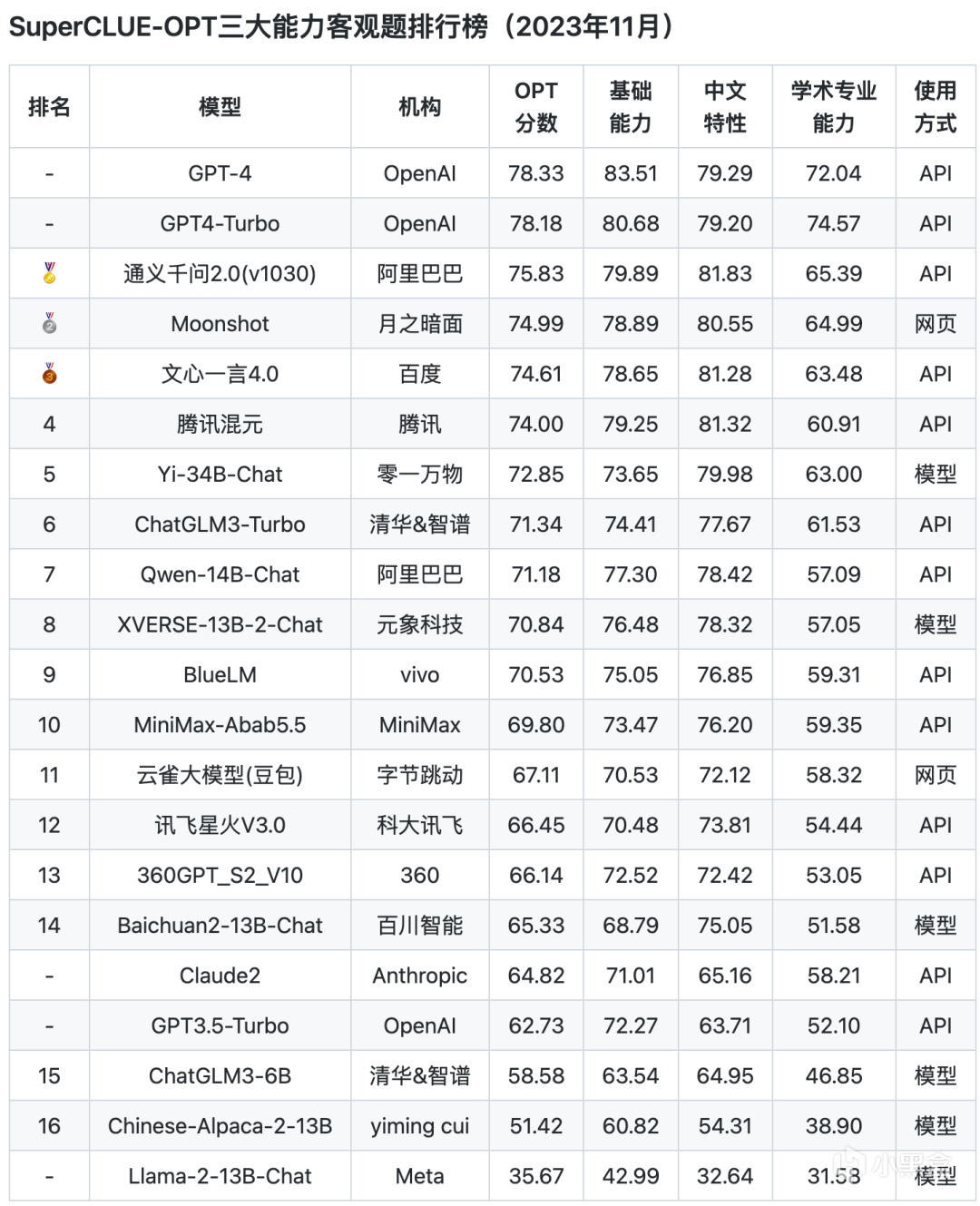
三大客观能力排行榜
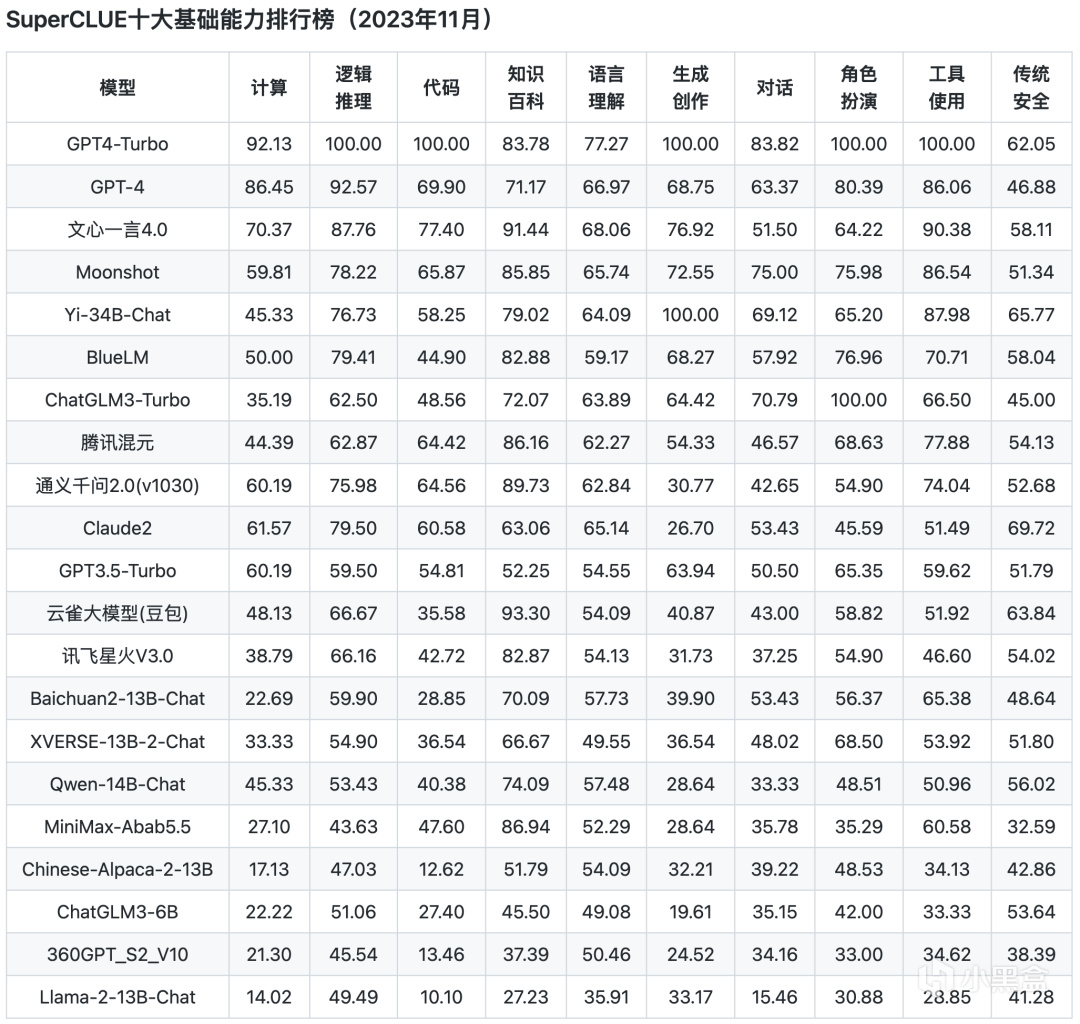
十大基础能力排行榜
从以上评测数据来看,ChatGPT的综合能力和单项能力都表现非常出色,各榜单中都是遥遥领先。而国内的文心一言、通义千问、腾讯混元、ChatGLM等头部模型距离GPT都还是比较明显。
让人惊喜的是,零一万物11月初发布的开源预训练大模型Yi-34B在全球开源大模型排行榜上取得了显著成就。
在斯坦福大学研发的大语言模型评测 AlpacaEval Leaderboard 中,Yi-34B-Chat 以 94.08%的胜率,超越 LLaMA2 Chat 70B、Claude 2、ChatGPT,在 Alpaca 经认证的模型类别中,成为世界范围内仅次于 GPT-4 英语能力的大语言模型。同一周,在加州大学伯克利分校主导的 LMSYS ORG 排行榜中,Yi-34B-Chat 也以 1102 的 Elo 评分,晋升最新开源 SOTA 开源模型之列,性能表现追平 GPT-3.5。
在开源模型中,Yi-34B-Chat 在英语能力上进入前十。LMSYS ORG 在 12 月 8 日官宣 11 月份总排行时评价:“Yi-34B-Chat 和 Tulu-2-DPO-70B 在开源界的进击表现已经追平 GPT-3.5”。
作为一家2023下半年才首度对外亮相的新公司,其发布的模型能够取得如此卓越的成绩,无疑为国内原本就热度高涨的AI产业注入了一剂强心针。这一成就不仅彰显了该公司在技术研发方面的实力和创新能力,也进一步提振了市场对AI行业的信心。(尽管Yi-34B有些争议)
路且长
在GPT3.5被端上餐桌前,AI似乎一直在幕后默默工作,鲜有引起公众关注的突破性产品。尽管如此,人工智能已经在我们的生活中发挥着重要作用,包括推荐系统和自动驾驶等技术。
当GPT-3.5在全球范围内引发热潮时,许多人不禁思考:“为什么中国没有出现类似ChatGPT的产品?”其实,不仅在中国,德国、英国、法国等欧洲国家也面临着同样的问题。这反映出全球范围内的创新和技术领导权之争。
对于中国而言,算力是制约AI模型发展的重要因素。目前,国内大模型在算力方面与国际先进水平存在较大差距,这是阻碍我国大模型发展的客观原因。没有足够的算力基础,后续的算法研究和开发将难以进行。
算力需求主要包括训练算力和推理算力。根据公开数据,ChatGPT的训练算力消耗巨大,达到了3640PF-days(相当于每秒计算一千万亿次,需要计算3640天)。换算成英伟达A100芯片,单卡算力约为0.6P,在理想情况下总共需要约6000张,考虑互联损失后,则需要一万张A100作为算力基础。
以A100芯片每张10万人民币的价格计算,硬件投资规模将达到10亿人民币。此外,数据中心还需要推理算力以及服务器等设施,总规模应在100亿人民币以上。
根据2020年全球计算力指数评估报告,美国以75分位居榜首,拥有Google、Facebook、Amazon、Microsoft、Apple等互联网巨头。中国得分66分,排名第二。中美两国在AI算力支出占总算力支出的比例均超过10%。截至2021年底,我国在用数据中心服务器规模达到1900万台,存储容量为800EB(1EB=1024PB),算力总规模超过140 EFlops(每秒浮点运算次数),过去五年年均增速超过30%,全球排名第二。
欧盟内部,德国、英国、法国等国的计算力指数分别为54分、53分和51分,分别位列全球第三、第四和第五。欧洲也有知名的软硬件企业,如SAP、ASML、ARM等。
算力的发展离不开算力芯片的支持。算力芯片种类繁多,包括GPU、DPU、NPU等,各有特点和优势。对于人工智能大模型所需的芯片来说,更高的信息处理精度和计算速度至关重要。在超级计算领域,双精度浮点计算能力FP64是衡量高计算能力计算性能的关键指标。英伟达的H100和A100是目前唯一具备这些能力的芯片。
2022年10月,美国限制英伟达和AMD向国内出售高性能计算芯片,国内互联网大厂意识到风险,去找英伟达购买。但因为从下单到拿货的周期较长,国内互联网厂商的优先级较低,国内互联网大厂买到的A100以及H100芯片数量是比较有限的。
国内AI芯片已经批量生产的产品,大多都是A100的上一代。各公司正在研发的相关产品,如昆仑芯三代、思远590、燧思3.0 等,都是对标A100,但由于“实体清单”的限制以及研发水平的原因,都还没有推到市场。
美国制裁的背景下,国产化替代方案需要积累,在很长一段时间内,芯片与算力会是国产大模型与ChatGPT之间一道巨大的鸿沟。
算力问题外,语言问题也很影响AI模型的训练。即使在国内大语言模型快速发展之际,互联网中的中文训练集仍然相对较少,而且语言的复杂性使得中文模型的训练难度比英文更高。虽然中国拥有庞大的互联网用户基数和丰富的数据资源,但在自然语言处理(NLP)领域,尤其是在大规模预训练模型的研究方面,仍面临一些挑战。
————————
一些AI相关的站点可以通过这个AI导航站访问:ai.kuaida.link
#免责声明#
①本站部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责。
②若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
③如果本站有侵犯、不妥之处的资源,请联系我们。将会第一时间解决!
④本站部分内容均由互联网收集整理,仅供大家参考、学习,不存在任何商业目的与商业用途。
⑤本站提供的所有资源仅供参考学习使用,版权归原著所有,禁止下载本站资源参与任何商业和非法行为,请于24小时之内删除!

