

快科技现场报道:北京时间2023年9月20日凌晨,Intel在美国加州圣何塞举办第三届Intel on技术创新大会,上演了一场AI的盛宴。
通过一系列创新的技术和产品,从云端到网络,从边缘计算到消费者客户端,Intel AI正无处不在,为各种各样的工作负载、应用场景提供加速。

大会现场,Intel展示了全新AI PC的众多使用场景。
比如正在视频会议中的时候,如果有人来访,酷睿Ultra PC就会智能提醒你。
在你起身离开电脑、与客人说话的时候,PC会自动将两个场景分开,视频会议中的参会者听不到你和客人的对话,客人也听不到视频会议的内容,互不打扰。
当你回到视频会议中,PC就会自动提炼你离开时的会议内容,甚至帮你翻译不同的语言。
所以,摸鱼终极神器?

比如非常流行的AI对话与辅助工具,在酷睿Ultra PC上既可以通过GPT联网运行,也可以通过Intel OpenVINO离线运行。
在离线状态下,无论是帮你回答日常问题,还是提炼工作内容,包括撰写邮件,都不在话下。
创业公司Rewind甚至可以帮你在视频中搜索过往内容。
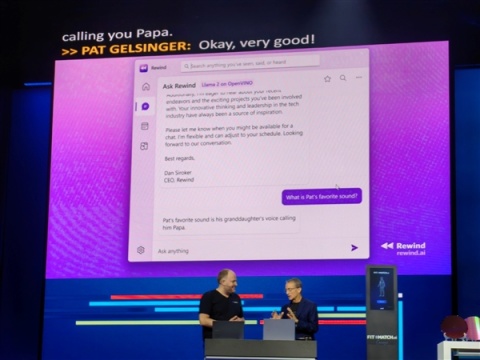
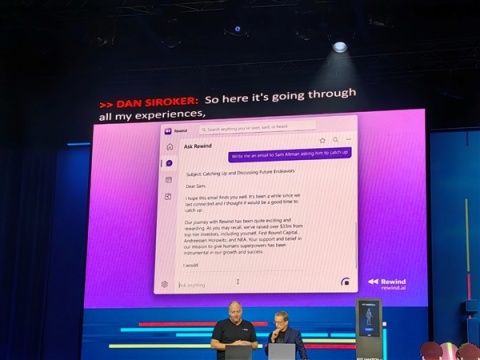
事实上,不少AI创业公司已经在使用酷睿Ultra加速自己的业务。
比如Deep Render,开发了全球首个实时神经视频压缩技术,可以利用AI加速,获得同等码率下更清晰的视频画质。

宏碁也展示了一款基于酷睿Ultra处理器的笔记本,在轻薄的身材下就可以轻松完成各种AI任务。
宏碁COO高树国表示,宏碁与Intel团队合作,通过OpenVINO工具包,共同开发了一套宏碁AI库,可以充分释放酷睿Ultra平台的性能潜力。

Intel还大方地公布了酷睿处理器后续路线图,明年将会看到下一代Arrow Lake,升级为Intel 20A制造工艺,并现场展示了一批测试芯片。
这将是Intel首个应用PowerVia背面供电技术、RibbonFET全环绕栅极晶体管的制程节点,意义重大,将按计划在2024年做好投产准备。
再往后的Lunar Lake继续使用Intel 20A工艺,预计重点升级架构。Intel甚至全球首次现场展示了Lunar Lake的实际运行,表明进展相当顺利。
继续往后是Panther Lake,制造工艺继续升级为Intel 18A,将在2024年拿到实验室样片,2025年推向市场。



在服务器和数据中心端,12月14日将会正式发布代号Emerald Rapids的第五代可扩展至强,也就是和酷睿Ultra同一天。
Emerald Rapids可以视为现有第四代Sapphire Rapids的一个升级版本,平台兼容,Chiplet设计由四芯片简化为双芯片,但增加到最多64核心128线程,在同样的功耗水平下提供更高的性能和存储速度。



2024年上半年,Intel将推出全部采用E核能效核的Sierra Forest,此前披露最多144核心144线程,现在又宣布,Sierra Forest还可以通过双芯片整合封装的方式,做到288核心288线程,预计可使机架密度提升2.5倍、每瓦性能(能效)提高2.4倍。
紧随其后的是全部采用P核性能核设计的Granite Rapids,AI性能对比四代至强预计可提高2-3倍。
Sierra Forest、Granite Rapids都会采用Intel 3制造工艺,已经完成了样片,今年下半年就能做好投产准备。
到了2025年,我们将看到代号Clearwater Forest的再下一代至强,和Sierra Forest一样采用能效核设计,保持平台兼容,但升级为Intel 18A制造工艺。
Intel正全力推动四年五个工艺节点的战略,它们既用于自家产品,也会用于外部客户代工,也就是Intel代工服务(IFS)。
其中,Intel 4将在酷睿Ultra处理器上首发,目前已投入量产,正在提升产能。
Intel 3不会出现在酷睿上,而是仅用于至强,包括明年的Sierra Forest、Granite Rapids,目前已经做好了投产准备。
Intel 20A主要用于消费级产品,包括Arrow Lake、Lunar Lake,将按计划在2024年做好投产准备。
Intel 18A预计会成为一代主力,消费级的Panther Lake、服务器级的Clearwater Forest都会用它,外部代工也已经拿下了Arm、爱立信等客户。
目前,Intel已经向代工客户发放了18A工艺PDK(工艺设计工具包)的0.9版本,距离正式版只有一步之遥。
多个测试芯片项目也都在进行中,预计2024年可以拿到实际硅片,2025年投产。
有趣的是,Intel首次在工艺路线图上列出了18A之后的三代工艺,分别临时称之为Next、Next+、Next++。
其中,18A之后的下一代,将首次正式使用ASML的全新高NA EUV光刻机。
为了推进多代工艺快速演进,Intel可是砸出了大量的真金白银,仅仅在美国就会投资多达1000亿美元,升级位于俄勒冈州、亚利桑那州、新墨西哥州、俄亥俄州的晶圆厂。
美国之外,Intel要在德国要建设新的晶圆厂,在波兰、马来西亚建设新的封测厂。
AI加速器方面,Gaudi 2已经落地,在中国也正全力推进应用。
下一代的Gaudi 3将把制造工艺从7nm升级到5nm(预计还是台积电),带来的性能提升堪称一次飞跃:
BF16算力提升4倍,计算性能提升2倍,网络带宽提升1.5倍,HBM高带宽内存容量提升1.5倍。
从示意图上看,Gaudi3的主芯片将从单颗升级为两颗整合,HBM内存则从6颗增加到8颗。
继续往后,就是代号Falcon Shores的全新一代加速器,Intel首次将x86 CPU至强、Xe GPU加速器融合在一起,官方称之为XPU,类似AMD Instinct MI300A。
按照Intel之前给出的数字,对比当今水平,Falcon Shores的能耗比提升超过5倍,x86计算密度提升超过5倍,内存容量与密度提升超过5倍。
随着Chiplet芯粒应用越来越广泛,各家都有自己的解决方案,迫切需要一个统一的行业标准。
为此,阿里云、AMD、Arm、谷歌云、Intel、Meta(Facebook)、微软、NVIDIA、高通、三星、台积电等行业巨头去年共同发起成立了“通用芯粒高速互连开放规范”(UCIe),组织成员已经迅速增加到120多家。
UCIe是一项开放标准,可以解决多IP集成整合的障碍,让不同厂商的芯粒可以协同工作,从而更好地满足不用负载和应用的扩展需求,尤其是AI。
在大会现场,Intel展示了基于UCIe规范的测试芯片封装,代号“Pike Creek”。
它通过EMIB先进封装技术,同时整合了基于Intel 3工艺的Intel IP芯粒、基于台积电N3E工艺的Synopsys IP芯粒。
说完硬的,再看软的。
目前,Intel Developer Cloud开发者云平台已全面上线,可帮助开发者利用最新的Intel软硬件进行AI开发,全面支持CPU、GPU、NPU,包括用于深度学习的Gaudi2加速器。
Intel还授权开发者可以使用Intel最新的硬件平台,比如即将发布的Emerald Rapids第五代至强,以及GPU Max 1100/1550数据中心加速器。
使用Intel开发者云平台时,开发者可以构建、测试、优化AI以及科学计算应用程序,还可以运行从大小不同规模的AI训练、模型优化、推理工作负载,以实现高性能和高效率。
这套云平台建立在oneAPI这一开放的,支持多架构、多厂商硬件的编程模型基础之上,代码具备很高的可移植性,因此开发者无需考虑硬件和编程模型的差异,从而节省开发时间、加速产品开发。
Intel AI推理和部署运行工具套件OpenVINO升级为2023.1版,包括针对跨操作系统和各种不同云解决方案的集成而优化的预训练模型,包括多个生成式AI模型,例如Met Llama。
ai.io、Fit:Match现场展示了如何使用OpenVINO来加速,比如ai.io借助OpenVINO评估运动员的表现,Fit:Match通过OpenVINO帮助消费者找到更合身的衣服。
最后是Strata项目,以及边缘原生软件平台的开发。
该平台将于2024年内推出,提供模块化构件、优质服务和产品支持。
这是一种横向扩展智能边缘和混合AI所需基础设施的方式,并将Intel和第三方的垂直应用整合在一个生态系统内,帮助开发人员能够构建、部署、运行、管理、连接和保护分布式边缘基础设施和应用程序。
毫不客气地说,Intel是当今最有资格让AI无处不在的顶尖企业,可以说唯一拥有全套软硬件AI解决方案。
无论是酷睿/至强CPU通用处理器、GPU/AI独立加速器、NPU神经网络加速单元,甚至是神经网络芯片、量子计算芯片,还是先进的制程工艺、封装技术,抑或各式各样开放的、统一的开发平台与工具套件,还有领先的行业标准规范,Intel都走在了AI时代的前列。
在某些特定方面,Intel可能不是最好的,但论综合素质,还真找不到可与之匹敌的。这也是为什么说Intel早已不是一家单纯芯片公司的一个重要原因。
目前,Intel的各项技术和产品创新都在加速,期待越来越精彩的表现!
#免责声明#
①本站部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责。
②若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
③如果本站有侵犯、不妥之处的资源,请联系我们。将会第一时间解决!
④本站部分内容均由互联网收集整理,仅供大家参考、学习,不存在任何商业目的与商业用途。
⑤本站提供的所有资源仅供参考学习使用,版权归原著所有,禁止下载本站资源参与任何商业和非法行为,请于24小时之内删除!

