

在今年六月份,英特尔宣布Meteor Lake架构酷睿处理器引来命名规则的重大改变,即P、U等低电压处理器更名成酷睿Ultra系列,并全系更新品牌标识,包括酷睿,Evo平台,vPro平台,分级方式划分成酷睿Ultra 5、酷睿Ultra 7和酷睿Ultra 9,酷睿新时代的序幕缓缓拉开。

在Core部分,也就是计算模块,可以看到英特尔展示的Core由6个P-Core和2组E-Core族群组成,每组E-Core族群内包含4个E-Core,因此在物理计算单元上为6个P-Core,8个E-Core,并且由于P-Core本身支持超线程技术,从而构成了14C20T的结构。而酷睿Ultra 5、7、9的划分,则主要依靠P-Core、E-Core频率和数量实现,与酷睿i系列时代相当。

UnCore部分则比以往要复杂得多,从大体上看,包含iGPU、I/O以及位于Die正中间的SOC部分。SOC模块与封装层面的SoC(System on Chip)概念略有不同,这里是指芯片级别的整合,可以将其理解为CPU的范畴内。
英特尔重新定义SOC模块是将UnCore提升到了一个更重要的级别。实际上在SOC模块中我们依然能够看到很多的熟悉的模块。比如负责无线连接的Wi-Fi 6E & Bluetooth,同时也将会通过外接的形式实现对Wi-Fi 7的支持。再比如原来放在iGPU中的媒体处理计算单元,也就是编解码器硬件,这里包含对AV1格式编码、8K HDR的支持。除此之外,SOC模块还包含输出单元、内存控制器等等。
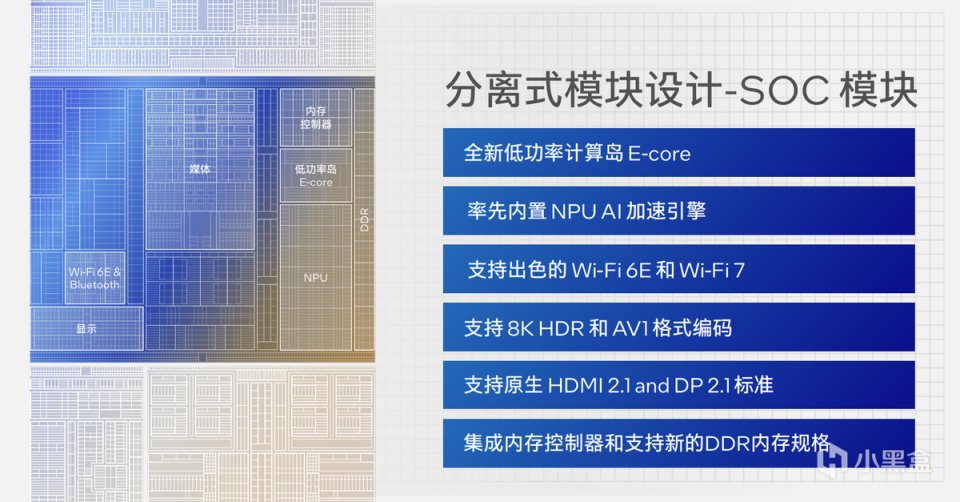
SOC模块中还包含一个新的低功率岛E-Core,以及用于AI加速的全新NPU。因此在Meteor Lake的计算方式上,从原来的P-Core、E-Core二阶计算模式基础上,通过增加SOC模块实现三阶混合计算架构。英特尔希望通过新的计算层级,实现更好的线程调度与功耗平衡。

在SOC模块中,我们需要关注首次集成人工智能加速引擎的NPU。这不是英特尔处理器第一次涉及人工智能加速,部分13代酷睿处理器中就包含了Movidius VPU用来实现CPU与GPU分载形式完成AI加速。英特尔希望通过新增的NPU模块实现更低功耗的人工智能加速,比如连续3个小时视频通话的背景虚拟化加速,再比如利用轻薄本运行时下流行的Stable Diffusion。
更重要的是,NPU与Meteor Lake的连接使用了Foveros 3D封装技术,这是英特尔首次大规模在消费领域使用Foveros。在此之前,Foveros基本应用在服务器处理器、高密度计算GPU、FPGA以及2019年小批量尝试的Lakefield中,属于非常高科技的迭迭乐,具体封装细节我们会在后续封装中进行详细说明。
在SOC模块上方,则是Meteor Lake引入的全新iGPU核显,按照英特尔的说法,新核显在性能上有更明显的提升,并且能够更好的支持DirectX 12功能集,让轻薄本获得更好的图形效果。

最后一个重要模块则是负责整个处理器对外设备的I/O模块,包括PCIe支持以及Thunderbolt连接。其中PCIe最高支持PCIe 5.0版本,Thunderbolt则仍然是Thunderbolt 4,前段时间发布的Thunderbolt 5在未来一段时间中将以独立芯片的设计存在。

Intel 4制程工艺参上
Meteor Lake性能与功能进步很大原因取决于Intel 4制程工艺能够支持其进入量产。按照英特尔的说法,Intel 4目前进度符合预期,能够很好的帮助英特尔进阶到接下来的Intel 3、Intel 20A和Intel 18A制程工艺中,属于重要的制程节点。

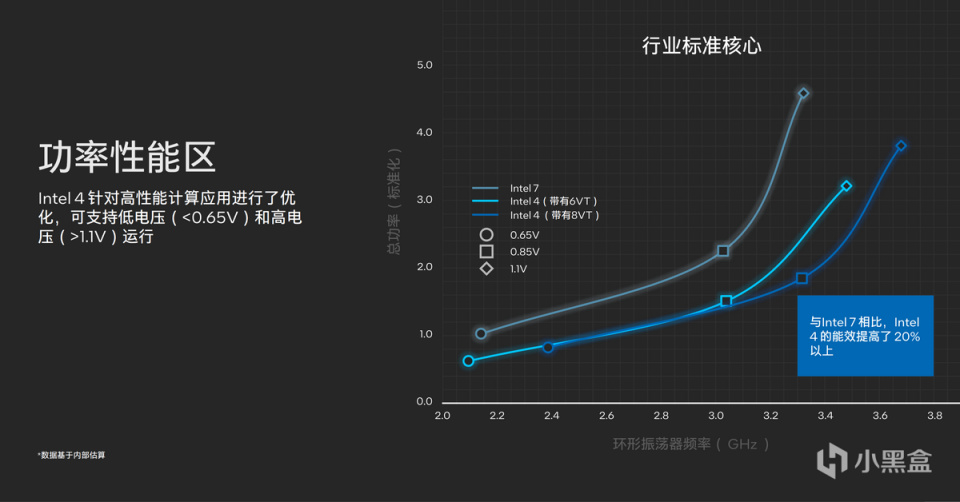
Intel 4制程工艺帮助英特尔CPU实现了更高性能的逻辑库,让Die的面积相对Intel 7有两倍的缩减,同时所采用的EUV光刻技术不仅满足了将Die变小的工艺,也进一步在制造中简化了流程,并帮助CPU提升了20%的性能与能耗比。

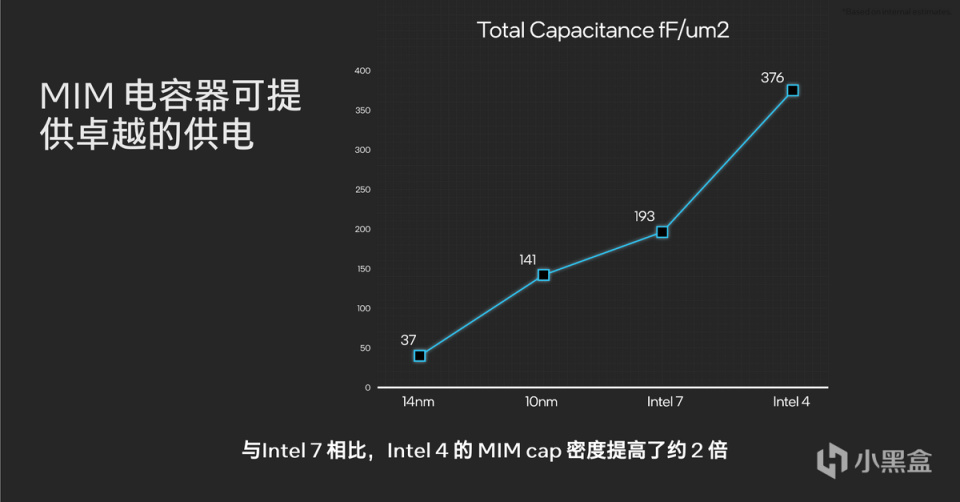
与此同时,在CPU设计上,英特尔通过8VT的场效应晶体管(FET)的阈值电压(Threshold Voltages)实现更好的频率与电压关系,同时进一步加大MIM(Metal-Insulator-Metal)电容器设计密度,实现高密度MIM的高效底层供电。
当然,重点是Intel 4制程工艺带来的整体Die集成度变化,以高性能库高度为例,Intel 7的高度可以做到408nm,Intel 4则可以进一步缩减到240nm,缩减了将近0.6倍,也就是40%的尺寸缩减。同时,鳍片间距和M0(金属0)间距均有不同程度缩减。
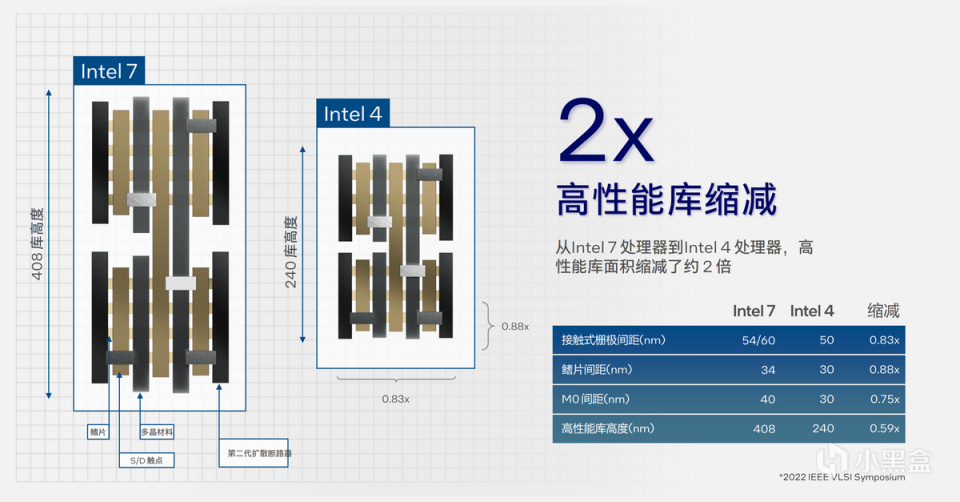
在18层金属层堆栈上,由于多层级EUV技术,英特尔通过四重自动成像工艺,实现了更高的密度,进一步使得30nm金属层间距缩小,也为布线提供了很好的支持。

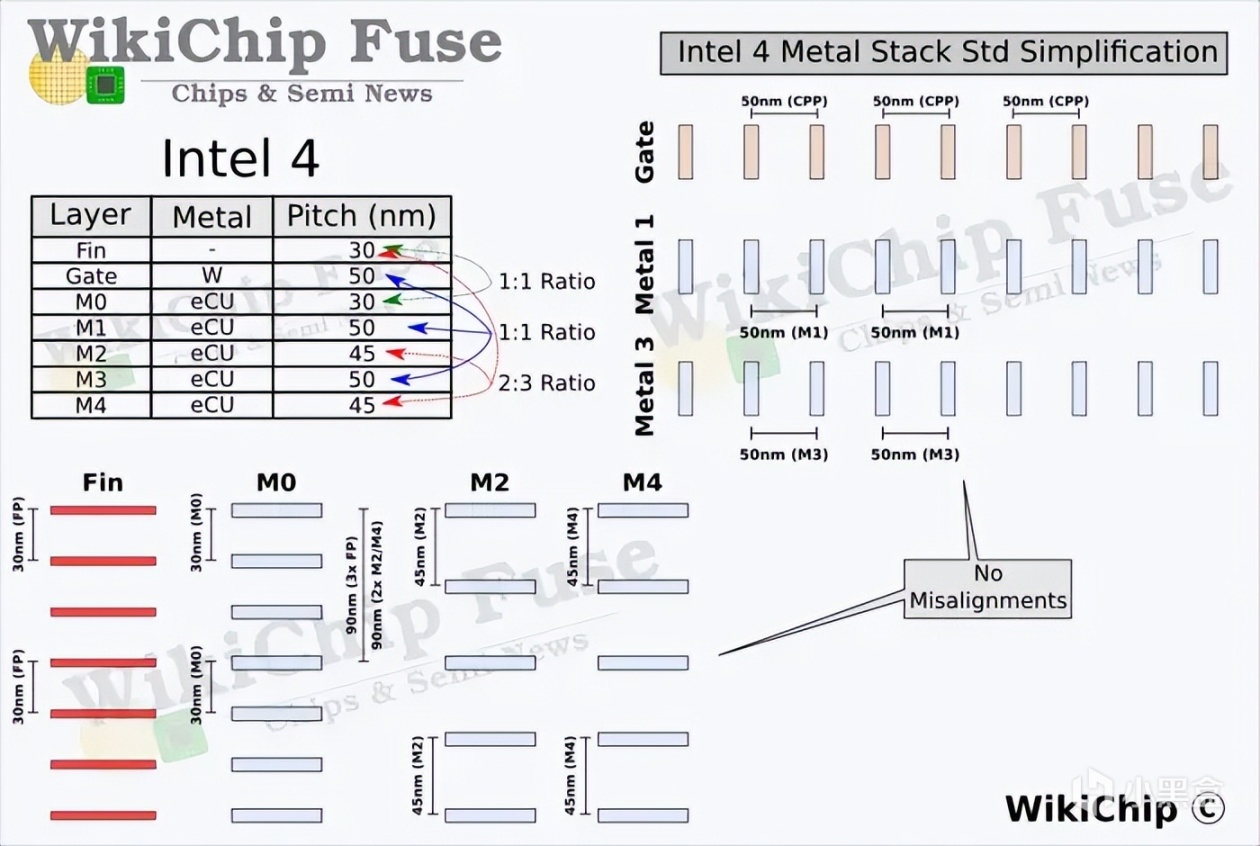
图片来源:WikiChip
通常而言,新制程工艺主要关注两个指标,一个是如何在间距变小的情况下提升导电率,即降低电阻。同时也要保证电子迁移的寿命足够长,让其处在一个理想的工作区间。在Intel 7制程中,英特尔尝试使用不同材质的特殊金属层说来达到两者平衡,但实际情况事与愿违。例如铜合金虽然能够降低电阻,电子迁移寿命成了问题,但如果使用钴金属,电子迁移寿命延长,但电阻随之变大。因此Intel 4尝试使用新的增强型铜金属工艺,也就是钽/钴与纯铜合金来解决这个问题。

EUV极紫外光刻技术是另外一个帮助Intel 4实现提升的重要技术。如前面所言,在EUV投入使用之后,不仅提升了晶体管密度,并且答复减少了流程复杂度,原本1个栅格+4个收集层的工艺,现在只需要单层EUV即可实现,从整体上降低了3到5倍的处理步骤。因此可以这么理解,在使用更高阶的EUV之后,工艺没有变复杂,反倒变得简单高效了。

不仅如此,新的EUV技术让连接结构变得更标准化,原本Intel 7需要多个标准实现不同的连接模式,在EUV上可以做到统一。并且自动分布和自动路径工具APR Tool也可以在布局、单元摆放、时钟数统一和布线上做到更高效的自动化设计,在不降低效率的前提下,进一步降低对人工经验的依赖,这无疑是很大的进步。

英特尔强调,在使用Intel 4制程工艺和EUV后,处理器的良率表现非常好,相比14nm和10nm时代都是一个明显的进步,更重要的是Intel 4的良品率提升,也会推进会进一步加快未来Intel 3、Intel 20A和Intel 18A的进度。
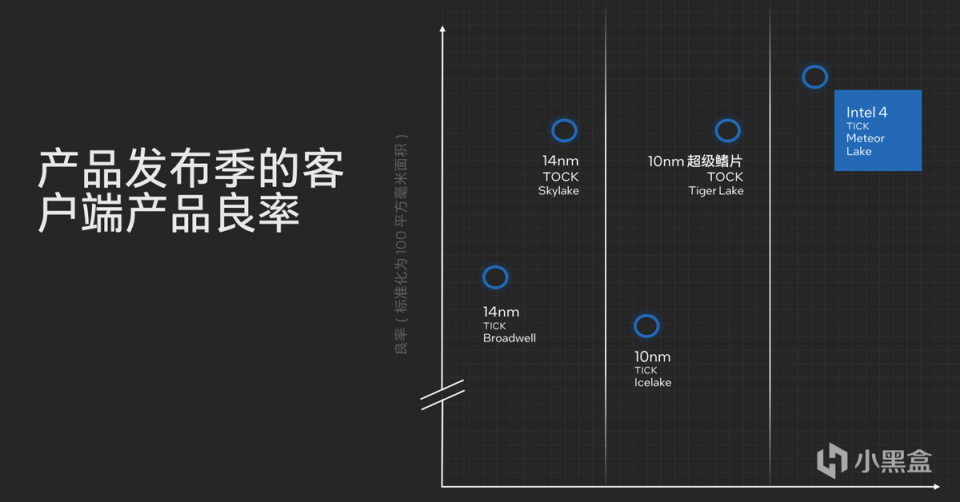
3D封装的胜利
戈登·摩尔曾经表示,在构建大系统时,将其分解为单独封装并互连的较小功能可能更经济。在构建复杂系统时,通过分解成单独封装并提供小型化的互联模块可以带来更好的经济性。

随着小型化互联技术的成熟,多模块、小芯片Chiplet设计开始变得司空见惯,在Meteor Lake上,通过小型化模块连接实现2.5D和3D封装,实现Die与Die之间的高密度连接,无疑可以让产品功耗、成本、性能都占尽优势。

英特尔尝试具备互联模块的封装其实由来已久。从2013年开始,就尝试将酷睿处理器和芯片组放在同一个封装内。在2017你那则实现了EMIB(嵌入式多芯片互连桥接)的2.5D封装来量产FPGA Stratix 10。在2023年,至强处理器Sapphire Rapids,更是进一步大规模使用了EMIB技术。
不仅如此,在2020年,英特尔首次在一款独立笔记本上实现了Foveros 3D封装技术,最终构建了具有里程碑意义的Lakefield移动处理器。Lakefield不仅实现了1个Ice Lake与4个Atom的混合架构,并且吧内存和处理器封装在了一起,混合架构的概念则自然延续至今,12代酷睿的P-Core与E-Core混合架构便是如此。
在2022年,英特尔首次推出了2.5D与3D封装技术混合的GPU产品,帮助GPU实现高密度复杂计算的应用场景。

EMIB的2.5D封装技术其实很好理解,即两个Die之间需要通过一个基板进行互联,也就是通过第二层基板实现不同Die之间的连接。不同于常见的PCB电路板,负责基板的连接密度可以实现55微米的间距。

Foveros 3D封装则是更进一步,它绕过了基板连接的环节,而是通过Die与Die之间的迭加和高密度连接,功率损失更小,连接性更好,第一代Foveros触点间距为50微米,而第二代Foveros则可以做到36微米触点间距,连接密度增加一倍。
值得一提,第三代Foveros也早已提上议程,被称为第三代Foveros Omni。Foveros Omni使得原本第一代Foveros的顶部芯片尺寸限制被取消,可以允许每层多个尺寸芯片迭加。因为Foveros Omni允许铜柱通过基板一直延伸到供电部分,因此解决了大功率硅通孔(TSV)在信号中造成局部干扰的窘境。此时Foveros Omni触点间距降低到25微米。
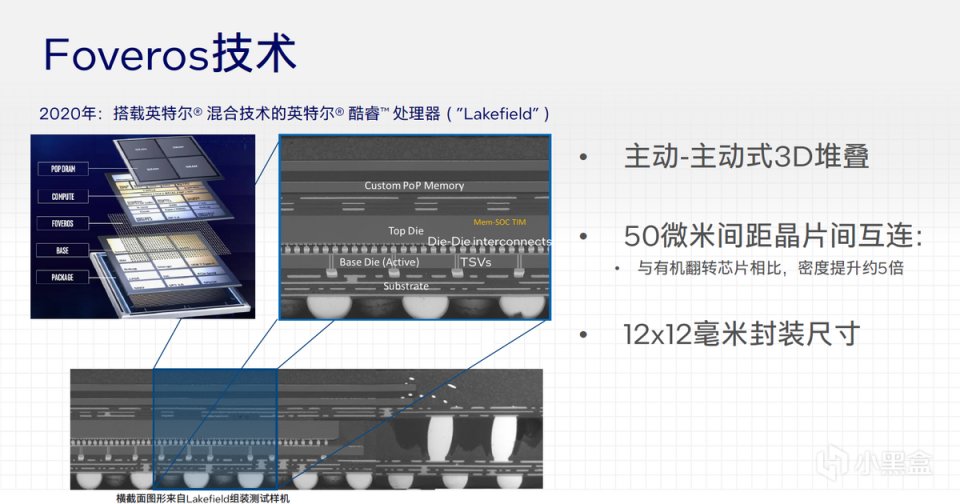
模块化与2.5D或者3D封装相结合是非常有好处的,它可以让每一个标准晶圆只专注CPU模块中的一个Tile。英特尔推算在标准晶圆上,100平方毫米面积的芯片可以压缩到50平方毫米面积,每个晶圆可以获得10%以上的芯片数量。


让我们回到Meteor Lake封装流程,主要过程包括制造晶圆,分割晶片,测试,晶圆组装,封装组装,最终测试几个步骤。
如前面所言,Meteor Lake是由4个Tile组成。分别是计算Tile、SOC Tile、GPU Tile以及I/O Tile。这4个Tile来自于不同的工厂,在拿到之后先进行Die与Die以及Base Tile的封装测试。测试通过之后进行二次分割,再进入传统处理器封装流程,最后进行系统级别测试。
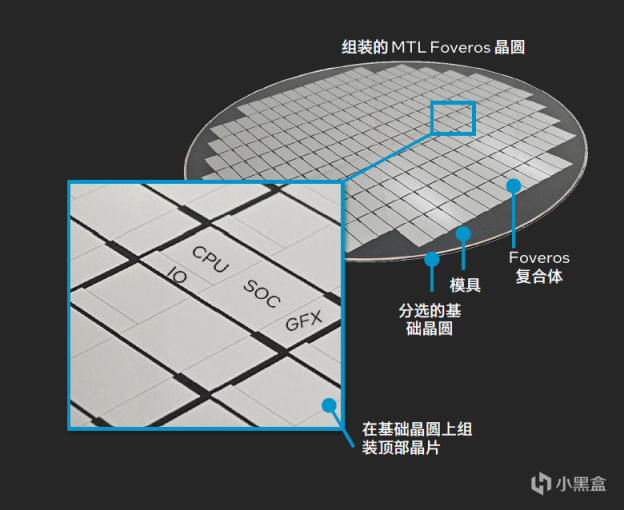
3D封装对最终测试要求很高,因此封装工厂也需要加大投资以配合Meteor Lake生产。英特尔也特意在原来的基础上,新增了新墨西哥以及槟城两个地方的封装工厂,确保封装量产规模化运作。
Meteor Lake AI:人工智能普适的第一步
最后一个话题是围绕Meteor Lake NPU打造的人工智能生态。Meteor Lake将会从硬件和软件层面获得完整的生态加持。事实上,我们所熟悉的AI不再限制于云端计算,而是开始向终端转移。
原因在于云端部署一旦扩大,对于资金成本的压力会进一步增加,云端服务商很难从单一的AIGC服务中平衡成本。不仅如此,云端AIGC需要全程联网,对隐私的保护并不可靠。

更重要的是,从终端层面看硬件其实已经具备了一定的加速能力,Meteor Lake在做的是将其功耗进一步降低,并让更多人从AI应用加速中获得更好的体验。这个部署实际上从数年前英特尔与合作伙伴的合作中开始,视频增强、美化、背景模糊、超分辨率计算均是AI终端加速的实际案例。随着生成式AI应用的火热,AI的应用场景变得更为丰富,文生图、图生图,文字生成视频都将成为可能,这也给Meteor Lake的NPU提供了用武之地。
在英特尔计划中,NPU引入仅仅是一方面,更重要的是软件生态、工具、合作伙伴的全面发展。在英特尔XPU战略中,GPU、NPU、CPU实际上都可以承载对应的AI算力,不同核心之间可以相互协同。例如CPU负责轻量级AI场景,GPU负责高性能、高吞吐场景,NPU则是在低功耗的状态下,实现高效的AI终端化应用。

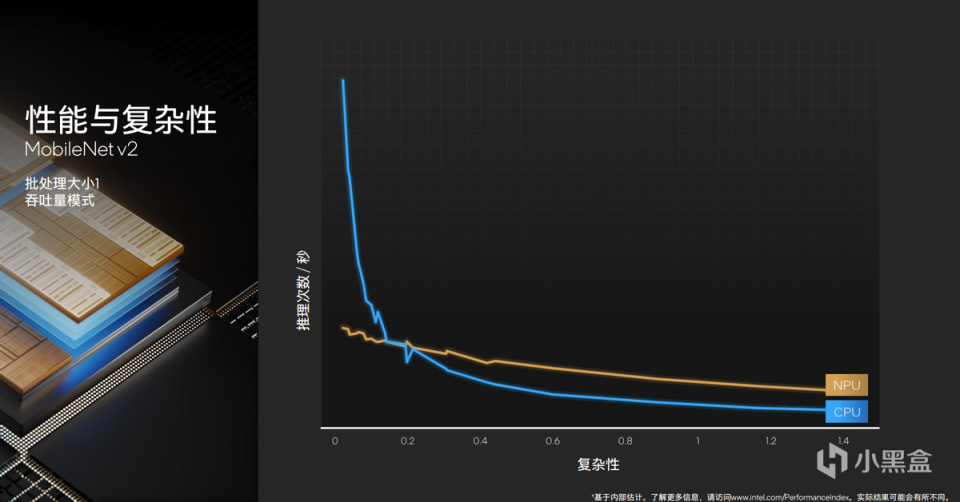
以MobileNet v2为例,在复杂度较低的应用场景中,可以看到CPU更为高效。而随着复杂度增高,NPU则更为擅长。
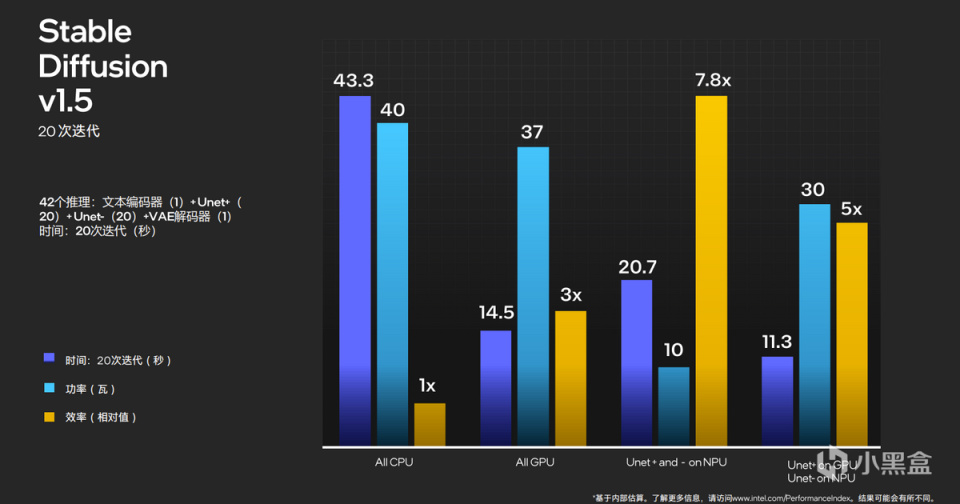
另外一个例子则是时下火热的Stable Diffusion。Stable Diffusion网络结构中主要氛围文本编码器,Unet+、Unet-构成的图像生成,VEE图像解码器,最终才是输出。


如果让Unet进行20次迭代,整个过程中只依靠CPU,功耗将达到40W,耗时43.3秒。如果将工作全部交给GPU,效率将提升3倍。但其实在英特尔XPU生态中,CPU、GPU和NPU可以同时调用,如果让NPU和GPU承担一部分的Unet工作,不仅效率提升明显,并且功耗还可以进一步降低。
目前,英特尔已经开始与软件开发商接触,进一步推动终端AI的生态应用,以丰富PC用户在AI加速上的体验。不仅如此,英特尔也持续与微软合作,在Office套件、Windows Studio Effects和DirectML中展开合作,经一部发挥XPU的优势。

不同应用可以根据不同的需求对疫情进行调用,比如Teams通过OpenVINO引擎实现人物背景虚化等功能,最终会通过Windows Studio Effects调用NPU。Adobe Photoshop则是GPU的忠实用户,在AI加速时会调用DirectML进行加速。
有意思的是,OpenVINO还可以根据XPU的情况及逆行动态调整,会主动分配CPU、GPU和NPU资源,实现动态优化加速。

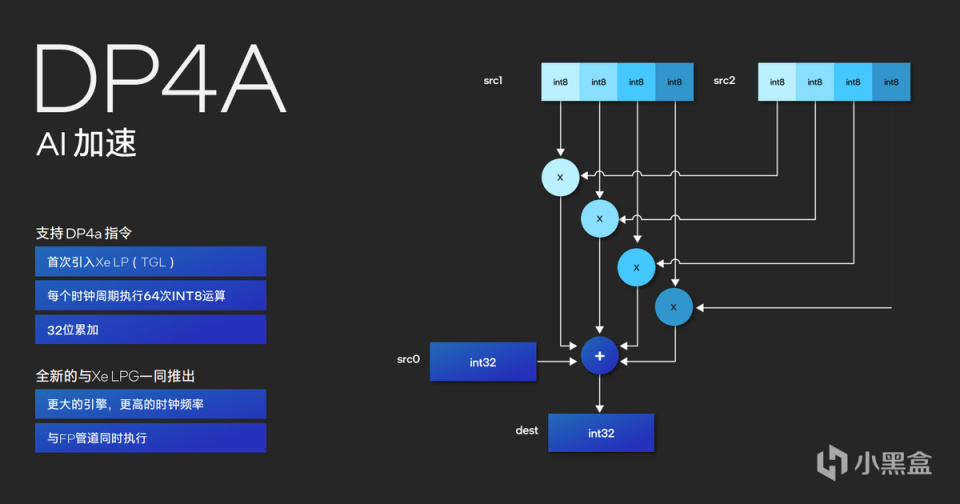
值得注意的是,Meteor Lake的GPU由于获得独显的IP,在执行AI的过程中实际使用的DP4a指令集,一个周期可以提供64int的整形计算累加,并且频率很高,配合矢量引擎和EU单元,就能获得很好的AI加速效果。
重点在于NPU实际上是由2个神经网络处理引擎组成,用于相乘后累加,即我们常说的MAC。这个过程在NPU中是由硬件实现的,并备激活函数的硬件单元。

NPU的两个单元支持INT8整数运算或者FP16浮点运算,提供MMU,专门的内存接口,可以直读内存的DMA,以及自用的RAM。如果运算中还涉及INT4或者FP32计算,则可以通过两个独立的DSP提供支持。

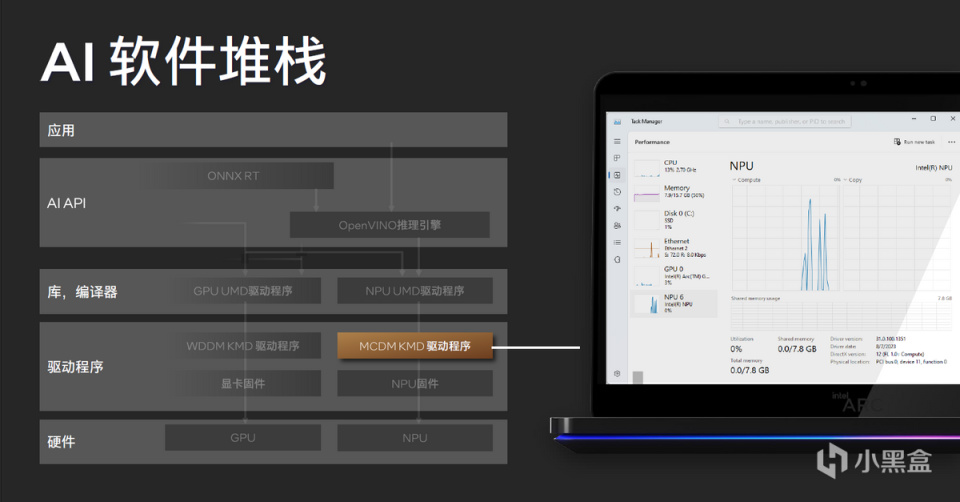
在软件层面NPU符合微软MCDM驱动框架,因此在Windows任务管理器中可以看到NPU的存在,属于计算设备中的一种,可以随时查看NPU的负载情况。

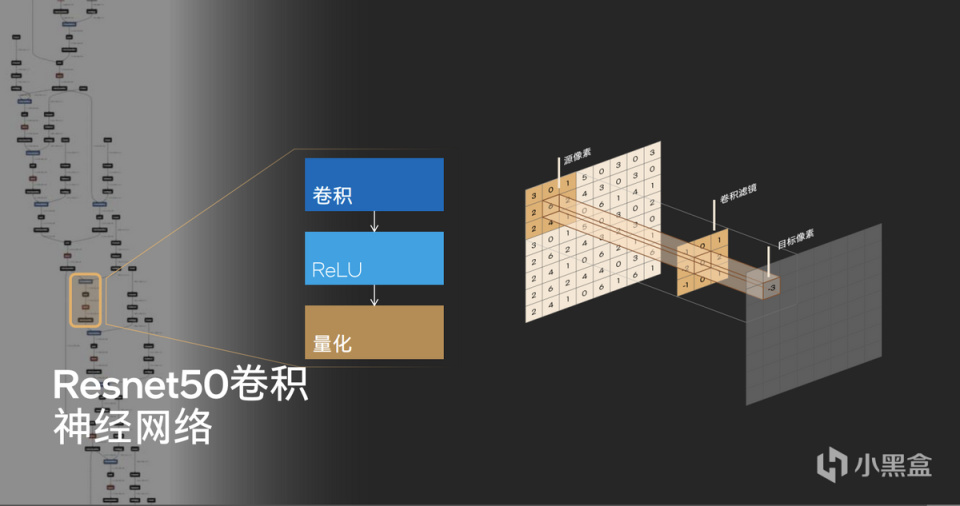
AI加速神经网络中的ReLU非线性激活函数也是由硬件实现的量化转换的,原本大模型训练中使用的FP32浮点计算实际上对精度并不敏感,实际推理中会通过ReLU转换成INT8,以实现高效和节约空间的目的。
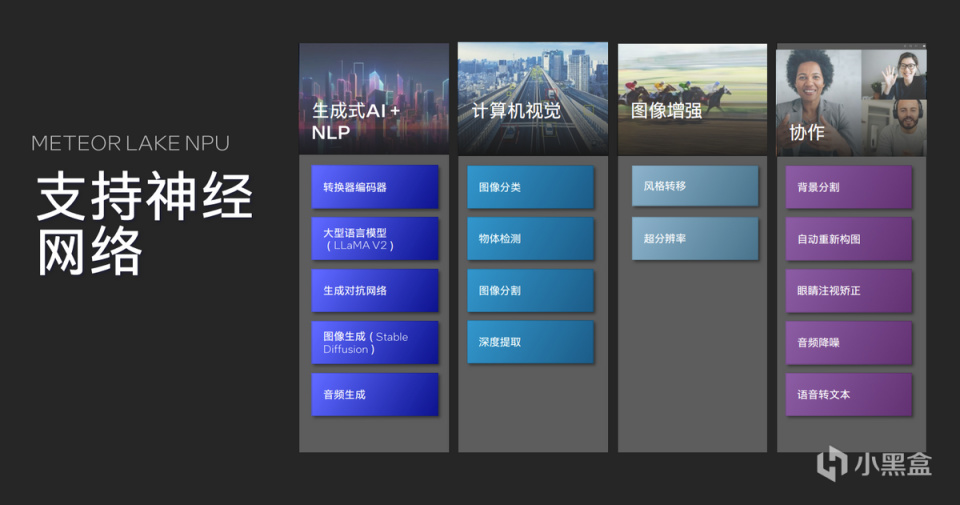
目前为止NPU已经获得了完整的软件接口、编程接口支持无论是AIGC、计算机视觉加速、图像增强还是Teams等协作软件中的背景虚化工作,都是NPU擅长的范围。同时英特尔借助Meteor Lake进一步推进XPU概念,让产品可以更好的支撑起整个AI生态系统,NPU在正式发布之前,已经成功迈出了第一步。
酷睿Ultra预示的新可能
相比起台式机处理器,酷睿Ultra的Meteor Lake架构被赋予了更多的可能性。按照英特尔的说法,EUV与Intel 4搭配实现了更好的效能以及更高的良品率,Foveros 3D封装和模块化设计让产品成本变得更为可控,NPU补充加速的AI生态,则进一步帮助英特尔向XPU策略迈出更为重要的一步。正因为如此,英特尔也在轻薄笔记本端尝试放弃酷睿i系列的命名规则,转向酷睿Ultra的命名方式,显然桌面端的命名规则转换,也不过是时间的问题罢了。

#免责声明#
①本站部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责。
②若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
③如果本站有侵犯、不妥之处的资源,请联系我们。将会第一时间解决!
④本站部分内容均由互联网收集整理,仅供大家参考、学习,不存在任何商业目的与商业用途。
⑤本站提供的所有资源仅供参考学习使用,版权归原著所有,禁止下载本站资源参与任何商业和非法行为,请于24小时之内删除!

